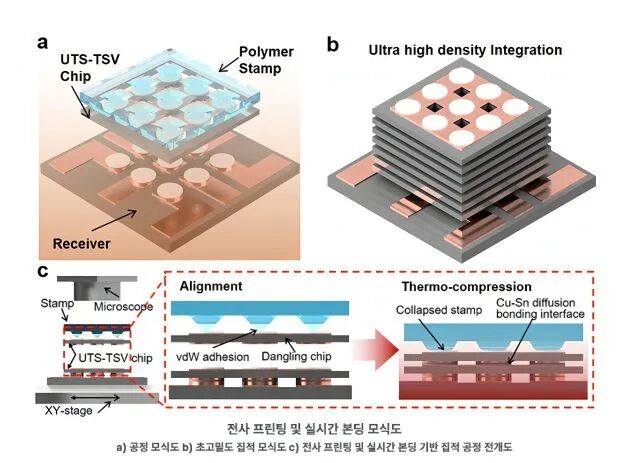
Репортаж от Wedoany,Американская полупроводниковая компания Marvell недавно представила коммутационный чип Teralynx T100, обеспечивающий пропускную способность 102,4 Тбит/с для инфраструктуры центров обработки данных (ЦОД) для ИИ и облачных вычислений.
Основной сценарий применения этого чипа — внутренние сети крупномасштабных кластеров ИИ. С быстрым ростом количества ускорителей GPU и XPU узким местом центров обработки данных становится не производительность отдельных вычислительных чипов, а эффективность обмена данными внутри кластера, задержки в сети, контроль энергопотребления и сложность архитектуры. Marvell заявляет, что Teralynx T100, изготовленный по передовому 3-нм техпроцессу, перепроектирован для нагрузок обучения и вывода ИИ, имеет типичное энергопотребление ниже 1000 Вт, что позволяет снизить энергопотребление до 25% по сравнению с аналогичными конкурентными решениями, и поддерживает масштабирование до 512 портов. Для операторов гипермасштабируемых облачных сервисов и инфраструктуры ИИ коммутационные чипы не являются наиболее заметными компонентами, но они напрямую определяют, могут ли десятки тысяч ускорителей образовывать стабильный, эффективный и малозатратный вычислительный кластер. Традиционные платформы коммутации ЦОД в основном проектировались для корпоративных сетей, универсальных облачных вычислений и иерархических архитектур. Когда задачи обучения ИИ достигают уровня десятков или сотен тысяч ускорителей, количество сетевых уровней, количество оптических межсоединений, управление перегрузками, хвостовые задержки и энергопотребление превращаются в системные затраты. Teralynx T100 стремится за счет более высокой пропускной способности, более высокой плотности портов и более плоской сетевой структуры уменьшить количество уровней коммутации и оптических линий внутри кластера ИИ, позволяя ЦОД развертывать больше ускорителей при существующих ограничениях по электропитанию и снижая давление сетевого оборудования на мощность стоек, охлаждение и совокупную стоимость владения.
Marvell сообщает, что образцы Teralynx T100 начнут поставляться клиентам в текущем квартале, и чип будет доступен в различных типах корпусов, включая BGA, медные соединения с общей упаковкой и оптические соединения с общей упаковкой.
Центры обработки данных ИИ вступают в новый этап, где ограничения накладываются одновременно «вычислительной мощностью, сетью, электропитанием и охлаждением». В последние годы рынок больше уделял внимание поставкам GPU, передовой упаковке и памяти HBM, однако роль сетевой инфраструктуры в крупномасштабных тренировочных кластерах быстро возрастает. Если эффективность сети кластера ИИ недостаточна, дорогие ускорители будут простаивать в ожидании связи, синхронизация задач замедлится, время сходимости обучения увеличится, что в конечном итоге превратит затраты на закупку оборудования в потери от неполного использования. Таким образом, коммутационный чип превращается из традиционного компонента сети ЦОД в ключевой полупроводник, определяющий возможность масштабного расширения инфраструктуры ИИ. Teralynx T100 поддерживает как горизонтальное, так и вертикальное масштабирование, совместим с требованиями новой архитектуры AI Ethernet и Ultra Ethernet Consortium, а также интегрирует возможности телеметрии, нативного управления перегрузками для ИИ и управления трафиком с низкой задержкой. Это означает, что операторы ЦОД при планировании кластеров ИИ в будущем смогут проектировать архитектуру, ориентируясь на более высокую плотность портов, меньшее количество сетевых уровней, более низкое энергопотребление и более гибкие формы межсоединений. Поскольку мощность стоек с GPU постепенно приближается к проектным пределам традиционных машинных залов или даже превышает их, снижение энергопотребления сетевых чипов становится не просто оптимизацией параметров оборудования, а влияет на резервирование электропитания всего ЦОД, долю жидкостного охлаждения, плотность стоек и темпы расширения. Для облачных провайдеров, интернет-компаний и операторов вычислительных мощностей ИИ повышение эффективности сетевой инфраструктуры напрямую повлияет на стоимость обучения, задержки вывода и способность предоставлять вычислительные ресурсы.
Этот анонс также показывает, что конкуренция в области инфраструктуры ИИ распространяется с отдельных вычислительных чипов на такие базовые компоненты, как коммутационные чипы, оптические межсоединения, SerDes, сетевые операционные системы и планировщики кластеров. Дальнейшие изменения будут сосредоточены на этапах валидации образцов у клиентов, темпах массового производства, совместимости с различными экосистемами AI Ethernet, а также на фактической стоимости развертывания решений с общей оптической упаковкой в крупных ЦОД. Если соответствующие технологии войдут в кластеры ведущих облачных провайдеров, сети ЦОД для ИИ станут новым приоритетом для инвестиций в передовые полупроводники и облачную инфраструктуру.
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com