Репортаж от Wedoany,Meta опубликовала результаты исследования интерфейса «мозг-компьютер» под названием Brain2Qwerty v2. В этом исследовании используется искусственный интеллект для восстановления естественного языка из мозговой активности, возникающей при наборе текста испытуемыми. Цель — предоставить неинвазивный способ текстовой коммуникации для людей, потерявших способность говорить или двигаться из-за травм мозга, инсульта или неврологических заболеваний.

В отличие от интерфейсов «мозг-компьютер», требующих хирургической имплантации электродов, проект Brain2Qwerty v2 использует оборудование магнитоэнцефалографии (МЭГ, Magnetoencephalography), которое регистрирует слабые магнитные поля, создаваемые нейронной активностью мозга пациента, для получения сигналов. Затем модель ИИ анализирует эти сигналы и выводит информацию.
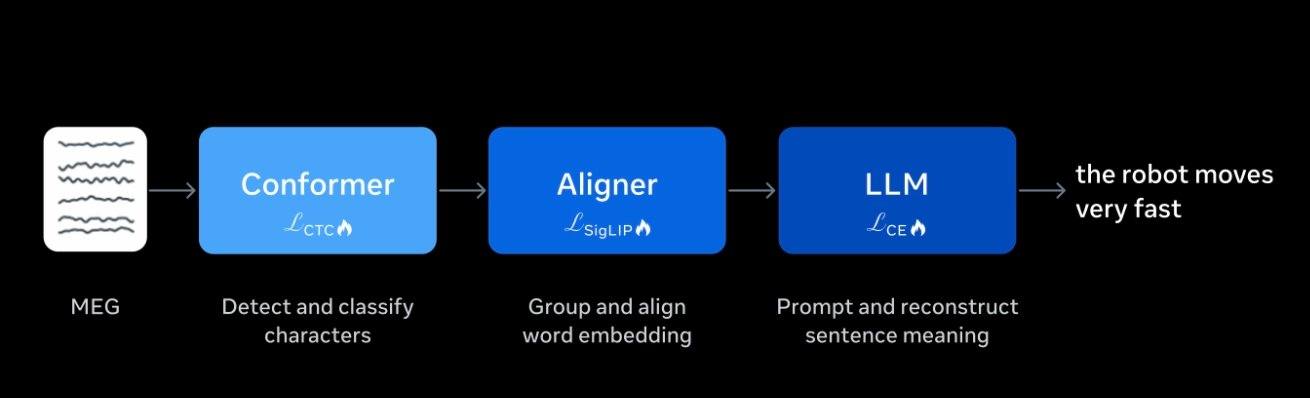
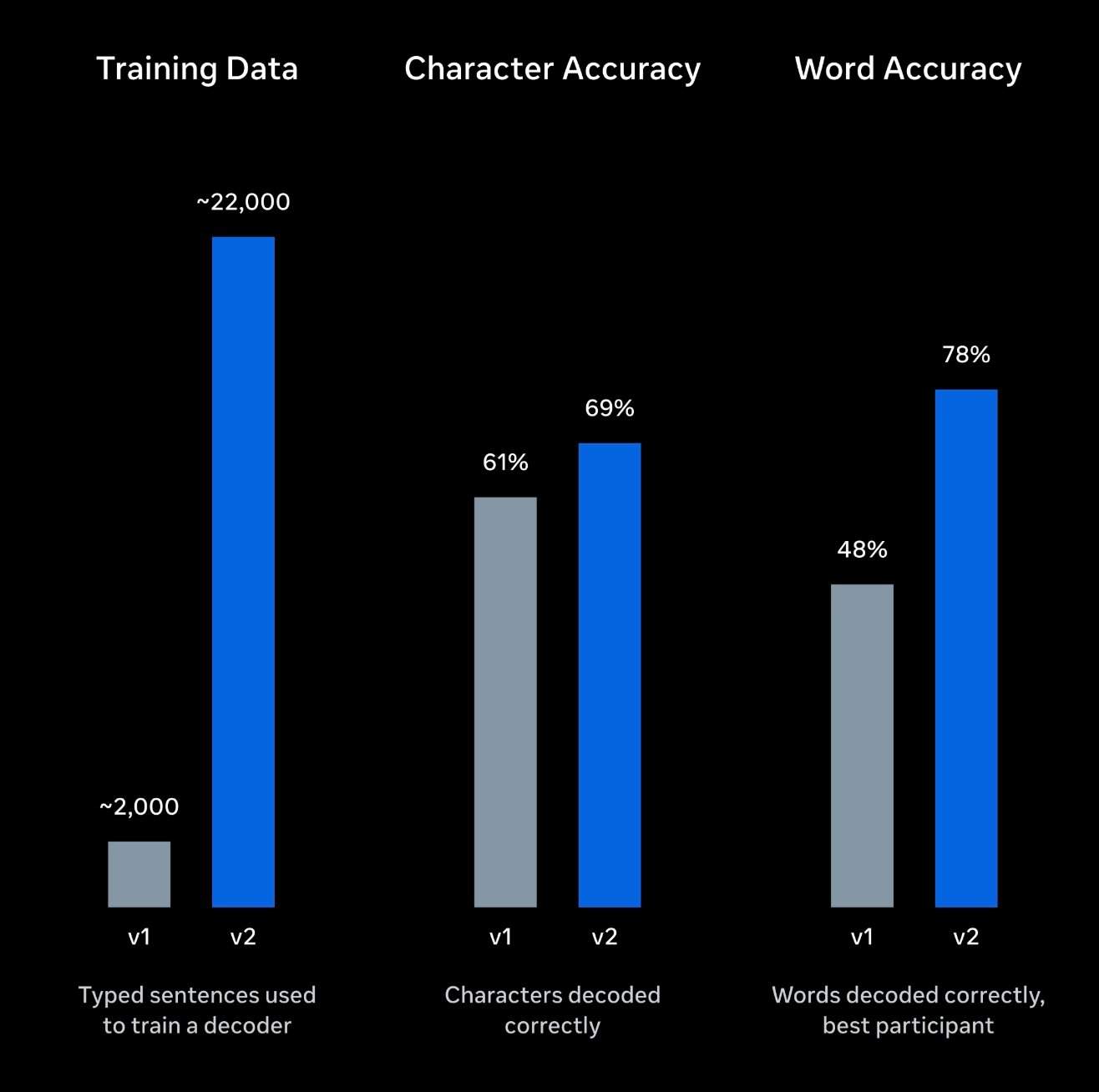
Модель ИИ была обучена на данных девяти добровольцев, включающих 22 000 предложений и около 10 часов записей мозговой активности. Meta специально донастроила модель, чтобы она могла использовать контекстную семантическую информацию для дополнения и исправления зашумленных мозговых сигналов, генерируя более связные и естественные предложения.
Согласно опубликованным Meta результатам экспериментов, средняя точность распознавания слов в Brain2Qwerty v2 в настоящее время составляет около 61%, что соответствует среднему показателю ошибок в словах (WER) около 39%. У лучшего испытуемого точность достигала 78%, причем более чем в половине тестовых предложений было не более одной ошибки на слово.
Данная технология по-прежнему имеет существенные ограничения. Эксперименты проводились в строго контролируемых условиях: пациенты должны были использовать крупное лабораторное оборудование МЭГ для точного получения магнитоэнцефалографических сигналов. С точки зрения стоимости оборудования, его размеров и возможности использования в повседневных сценариях, до практического применения еще далеко.
В настоящее время Meta опубликовала в открытом доступе на GitHub обучающие коды для Brain2Qwerty v1 и v2. Партнерская организация Basque Center on Cognition, Brain and Language также опубликовала набор данных v1. Набор данных v2 будет открыт после официального принятия соответствующей научной статьи.