Репортаж от Wedoany,Исследователи из Шанхайской лаборатории искусственного интеллекта (Shanghai Artificial Intelligence Laboratory) предложили новую парадигму под названием «Self-Harness», которая позволяет агентам на основе больших языковых моделей (LLM) систематически улучшать собственные правила работы, не полагаясь на инженеров-людей или более мощные внешние модели.
Производительность агентов на основе LLM зависит не только от базовой модели, но и от их фреймворка, который включает системные подсказки, инструменты, память, правила проверки, стратегии выполнения, логику оркестрации и процедуры восстановления после сбоев. Типичные сбои агентов часто возникают из-за фреймворка, а не самой модели. Например, агент может сообщить об успешном выполнении, не проверив ответ модели, или многократно повторять неудачные операции. SWE-agent, Claude Code, Codex и OpenHands являются популярными примерами фреймворков.
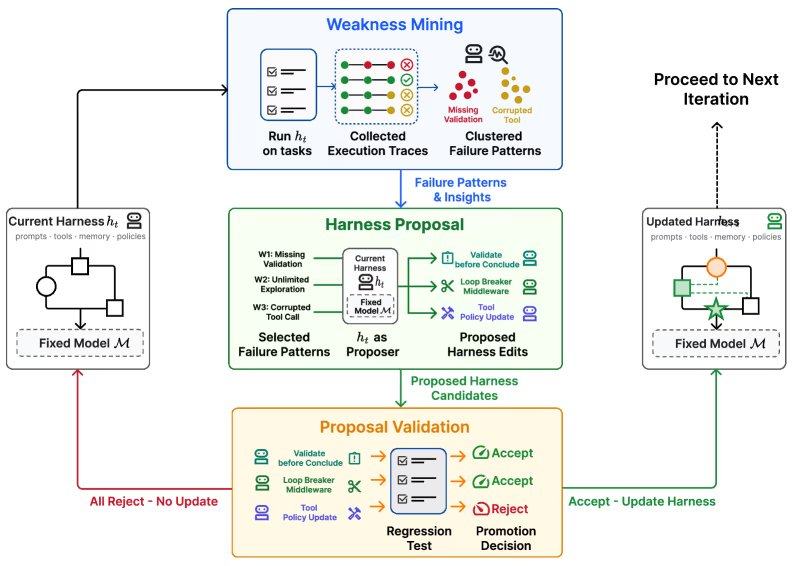
Ханфан Чжан, первый автор статьи о Self-Harness, отметил, что настоящим узким местом ручной инженерии фреймворков является зависимость от ситуативной отладки, а не от систематической обратной связи. Многие правки основаны на интуиции или небольшом количестве неудачных случаев, что затрудняет адаптацию к быстро развивающимся LLM. Парадигма Self-Harness позволяет агентам на основе LLM достигать самоэволюции через трехэтапный итеративный цикл.
Цикл начинается с этапа выявления слабых мест: агент выполняет задачи, генерируя траектории выполнения, классифицирует неудачные траектории и обнаруживает специфические для модели паттерны сбоев. Затем следует этап предложения изменений фреймворка: агент, используя роль «предлагающего», генерирует набор разнообразных и минимальных модификаций фреймворка, каждая из которых нацелена на конкретный механизм сбоя. Наконец, этап проверки предложений: система оценивает кандидатные изменения с помощью регрессионного тестирования, принимая их только в том случае, если правка не приводит к снижению производительности на сохраненных задачах. Если несколько кандидатов проходят тестирование, они объединяются в следующую версию фреймворка.
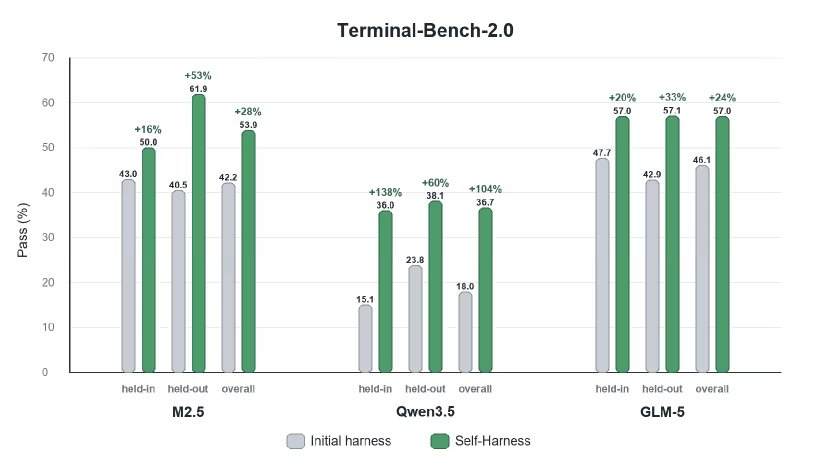
Исследователи оценили Self-Harness на бенчмарке Terminal-Bench-2.0, который тестирует выполнение на основе инструментов, включая управление артефактами, использование команд, проверку поведения и восстановление после ошибок выполнения. Они применили Self-Harness к моделям MiniMax M2.5, Qwen3.5-35B-A3B и GLM-5. Количественные результаты показали, что агенты повысили производительность за счет автоматического редактирования фреймворка, при этом относительное улучшение для разных моделей на сохраненных задачах составило от 33% до 60%.
Эксперименты показали, что Self-Harness вносит целенаправленные изменения, отражающие повторяющиеся проблемы каждой модели в процессе выполнения. Например, MiniMax M2.5 в базовом фреймворке бесконечно исследовала конфигурации наборов данных до истечения времени ожидания; система исправила это, добавив правило «прерывания цикла» (остановка после 50 вызовов инструментов и перенаправление метода), а также требование как можно раньше создавать начальную версию. Qwen-3.5 после ошибки перезаписи файла повторяла ту же команду; система ввела строгую дисциплину повторных попыток (запрет на полное повторение команд) и механизм немедленного воссоздания потерянных артефактов после файловых ошибок. GLM-5 с трудом сохраняла изменения окружения между разными командами; ее самогенерируемый фреймворк ввел правила персистентности переменной PATH, ограничения внешних вычислений и исправления любых неудачных проверок целостности перед завершением выполнения.
Чжан отметил, что автоматизированная инженерия фреймворков требует вычислительных затрат на повторную генерацию, параллельную оценку и регрессионное тестирование. Система также зависит от точности конвейера оценки, полагаясь в экспериментах на строгие, детерминированные верификаторы. Он считает, что оптимальными целями развертывания являются такие области, как кодирование, автоматизация внутренних рабочих процессов и конвейеры данных DevOps, где сбои измеримы, а пробы и ошибки относительно безопасны. Области с субъективной оценкой и высокими затратами, такие как медицинские решения, критически важная инфраструктура безопасности или юридические решения, следует избегать полной автоматизации. По мере усиления базовых моделей фреймворки будут расширяться, подключая более богатые внешние среды. Роль инженеров сместится от ручного исправления отдельных подсказок или вызовов инструментов к проектированию систем обратной связи, которые делают возможным улучшение агентов.
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com