Репортаж от Wedoany,Команда Alibaba Qwen выпустила Qwen-AgentWorld, включающий две модели, которые предназначены не для выполнения действий в среде агентов, а для прогнозирования результатов, возвращаемых этими средами, охватывая семь областей: MCP, поиск, терминал, программная инженерия, Android, Web и операционные системы.
Этот релиз продолжает недавние инвестиции Alibaba в автономных агентов: выпущенный в мае Qwen3.7-Max построен вокруг 35-часовой способности к автономному выполнению. Команда отмечает, что ключевым узким местом в масштабном обучении агентов являются ограничения обучения в реальных средах: поисковые системы не позволяют внедрять контролируемые условия, реальные терминалы не позволяют по требованию моделировать граничные случаи, такие как нехватка дискового пространства, и агенты не могут систематически подвергаться редким сценариям.
Исследовательская группа обучала агентов в сгенерированных симуляторах и обнаружила, что их производительность повышается сильнее, чем при обучении только в реальных средах. В другом тесте использование обучения модели мира в качестве этапа предварительной настройки перед тонкой настройкой агента повысило производительность по всем семи бенчмаркам, причем три из них никогда не встречались в процессе обучения. В сопутствующей статье отмечается, что моделирование мира является ключевым этапом на пути к созданию универсальных агентов.
В отличие от традиционных моделей агентов, оптимизирующих выбор действий, Qwen-AgentWorld обучается отвечать на обратный вопрос: учитывая только что выполненное агентом действие, что отобразит среда в следующий момент. В статье этот метод называется «языковой моделью мира»: модель учится предсказывать следующее состояние среды по всем семи областям в рамках единой цели обучения. Предыдущие исследования в этой области были более узкими: например, выпущенный Qwen в феврале WebWorld охватывал только веб-среду; выпущенная Snowflake в том же месяце Agent World Model генерировала управляемую кодом среду поддержки SQL, а не обучала модель предсказывать состояния. Qwen-AgentWorld — первая модель, охватывающая семь областей в единой архитектуре и интегрирующая моделирование среды с самых ранних этапов предварительного обучения.
В процессе обучения использовалось более десяти миллионов траекторий взаимодействия со средой, полученных от работы реальных агентов, и он был разделен на три этапа: первый этап обучал модели принципам работы среды, включая файловую систему, состояние терминала, изменения DOM в браузере и ответы API; второй этап обучал модель сначала рассуждать о последующем состоянии, а затем делать прогноз; третий этап с помощью обучения с подкреплением, используя проверки на основе правил и открытую оценку качества, ужесточал прогнозы. Обе модели используют архитектуру смеси экспертов, активируя лишь небольшую часть параметров на каждый токен. Модель с 35B активирует 3B, модель с 397B активирует 17B, обе поддерживают контекстное окно в 256K. Для областей GUI (Android, Web и операционные системы) модели работают с текстовыми деревьями доступности и иерархиями представлений пользовательского интерфейса, а не со скриншотами. Веса модели с 35B и AgentWorldBench доступны по лицензии Apache 2.0; веса модели с 397B пока не опубликованы.
Оценки по бенчмаркам показывают точность прогнозирования моделью содержимого среды, но результаты обучения раскрывают практическую ценность этой способности к прогнозированию для создания команд агентов — эти цифры более важны. По словам исследователей, агенты, обученные в контролируемых симуляциях, превзошли агентов, обученных в реальных средах. Внесение направленных возмущений повысило MCPMark с 24,6 до 33,8. В задачах поиска агенты, обученные в полностью вымышленных мирах, перенеслись на реальные поисковые задачи, повысив WideSearch F1 Item на открытой модели с 34,02 до 50,31. Тесты предварительной настройки показали, что предварительное обучение модели мира повысило BFCL v4 с 62,29 до 71,25, а Claw-Eval — с 53,60 до 64,88, без какой-либо специфической для агента тонкой настройки.
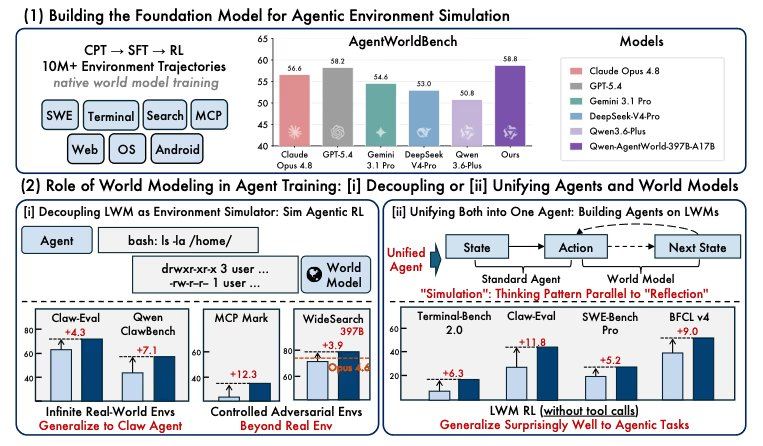
После публикации статьи среди исследователей ИИ развернулась дискуссия. Некоторые считают, что Qwen перевернул основную проблему, обучая модель предсказывать саму среду, и эти знания о прогнозировании затем переносятся на задачи агента, даже без специфической для агента тонкой настройки. Другие исследователи отмечают, что AgentWorldBench — это бенчмарк, созданный и опубликованный Alibaba в той же статье, и в тестах его модель победила с отрывом в 0,46, что может вызвать вопросы о независимости критериев оценки. Традиционная проблема методов RL с симуляцией заключается в том, что агенты склонны к переобучению на особенности симулятора; если модель мира слишком «чистая», агент учится модели, а не задаче. Результаты с разделением на отложенные данные и данные в статье частично отвечают на эти опасения: результаты поиска в вымышленных мирах показывают, что агенты, обученные в таких средах, могут переноситься на реальные поисковые задачи.
Для команд, создающих и масштабирующих конвейеры агентов, эта работа предлагает третий вариант: контролируемые симуляции, внедряющие граничные случаи, которые не встречаются в производственной среде. Синтетические среды — это легитимный слой обучения, дополнение к RL в реальной среде, а не обходной путь. Фундаментальная настройка на среду перед обучением агента, действующая на более ранних этапах разработки, чем большинство современных практик, позволяет повысить производительность по нескольким бенчмаркам без необходимости специфического обучения агента. То, что модель узнает до обучения, гораздо важнее, чем то, что учитывается в большинстве конвейеров.
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com