Репортаж от Wedoany,Мультимодальная пространственная интеллектуальная работа Spatial-TTT, первым автором которой является докторант Университета Цинхуа Лю Фанфу, выполненная совместно с несколькими исследователями, недавно была официально принята на ведущую конференцию по компьютерному зрению ECCV 2026. Эта работа посвящена решению проблемы потокового пространственного интеллекта мультимодальных больших моделей в реальном физическом мире, а именно тому, как модель формирует и постоянно обновляет пространственную память в непрерывно меняющемся видеопотоке, а не рассматривает каждый входной фрагмент как независимый.
Реальные сценарии, такие как навигация роботов, автономное вождение и дополненная реальность, требуют от моделей способностей, выходящих далеко за рамки понимания статических изображений. Традиционные методы при обработке длинных видеопотоков продолжительностью в десятки минут или даже часов, из-за отсутствия эффективного механизма обновления онлайн-памяти, приводят к фрагментации пространственного понимания. Spatial-TTT был предложен именно для решения этой задачи: он вводит концепцию тестирования во время обучения (TTT) в область пространственного интеллекта, позволяя модели обновлять свои внутренние параметры во время просмотра видео в процессе вывода.
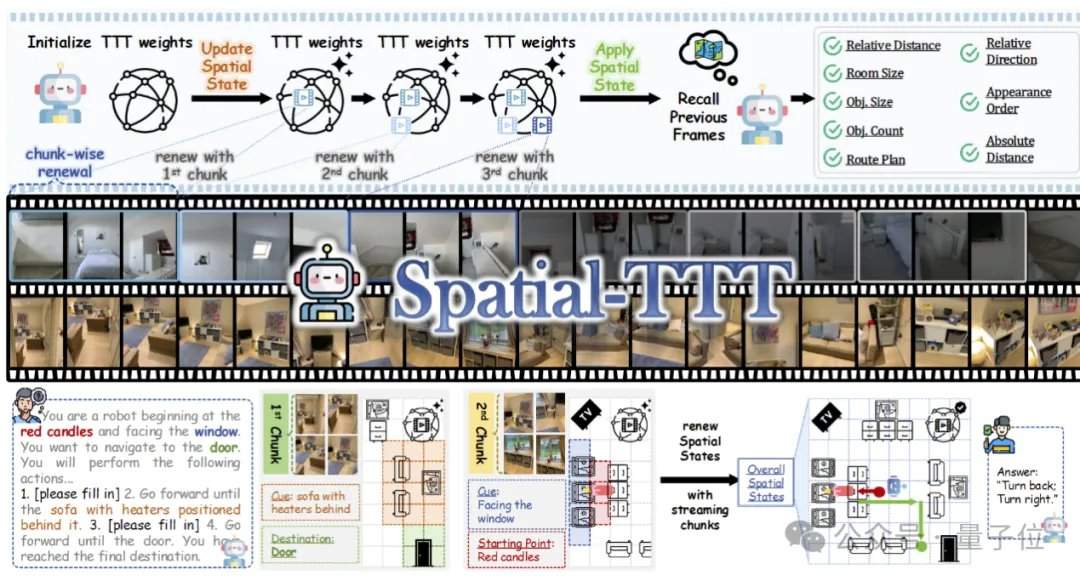
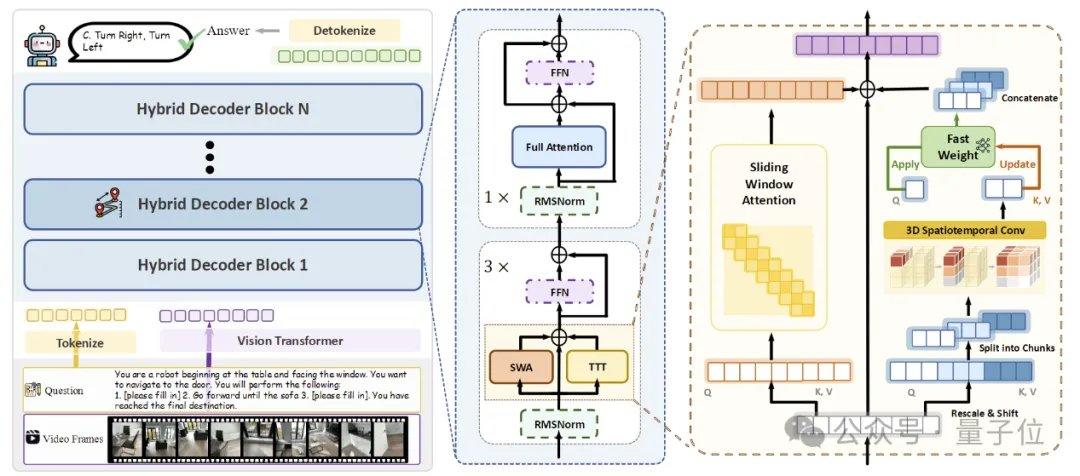
Для реализации эффективной потоковой пространственной памяти исследовательская группа предложила три ключевые технологии. Первая — гибридная архитектура TTT, в которой в декодере слои TTT и стандартные слои привязки самовнимания чередуются в соотношении 3:1. Первые отвечают за запись долгосрочной информации в быстрые веса, вторые поддерживают способность предварительно обученной модели к кросс-модальному выравниванию и семантическому выводу. Вторая — механизм пространственного прогнозирования, который путем введения легковесной 3D пространственно-временной свертки в ветвь TTT позволяет модели изучать прогностические связи между пространственно-временными контекстами, повышая стабильность онлайн-обновления. Третья — плотный надзор за описанием сцены, который путем создания данных описания сцены, охватывающих глобальный контекст, категории объектов и пространственные отношения, обучает модель переходить от «локального ответа на вопросы» к «поддержанию глобальной 3D-памяти».
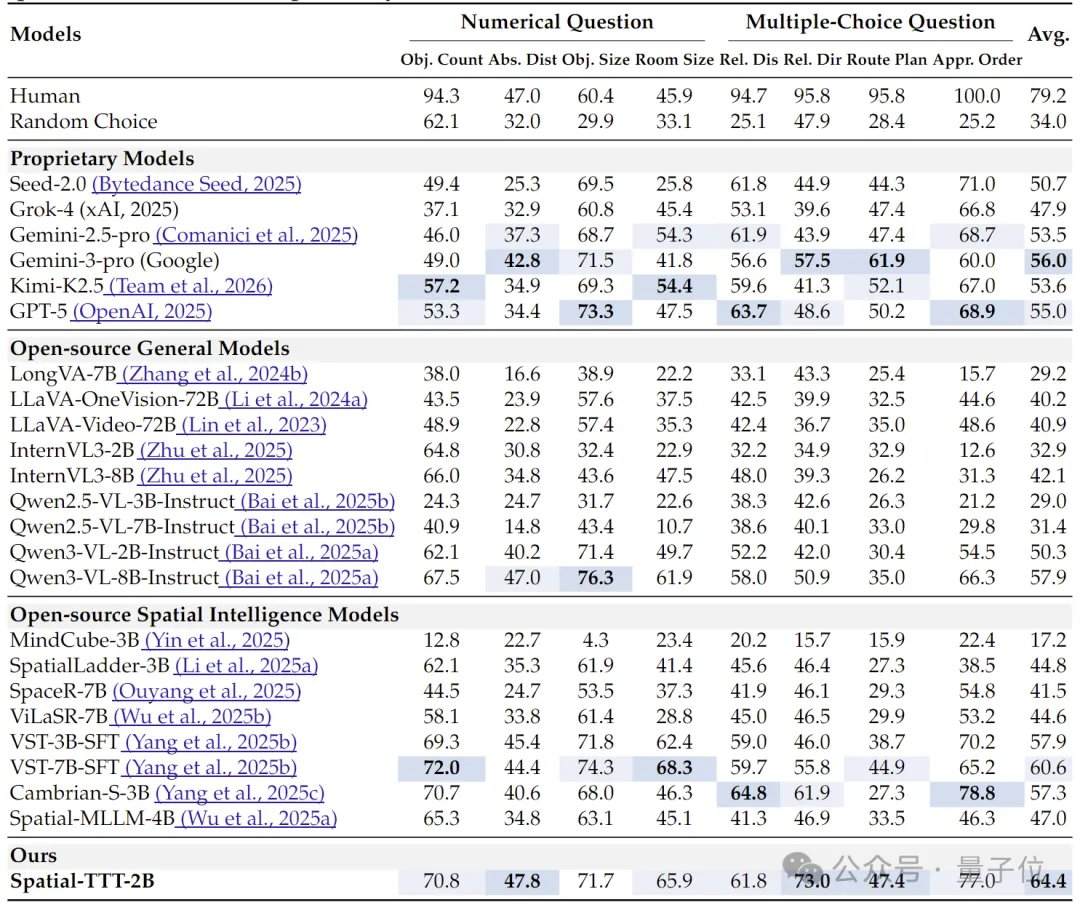
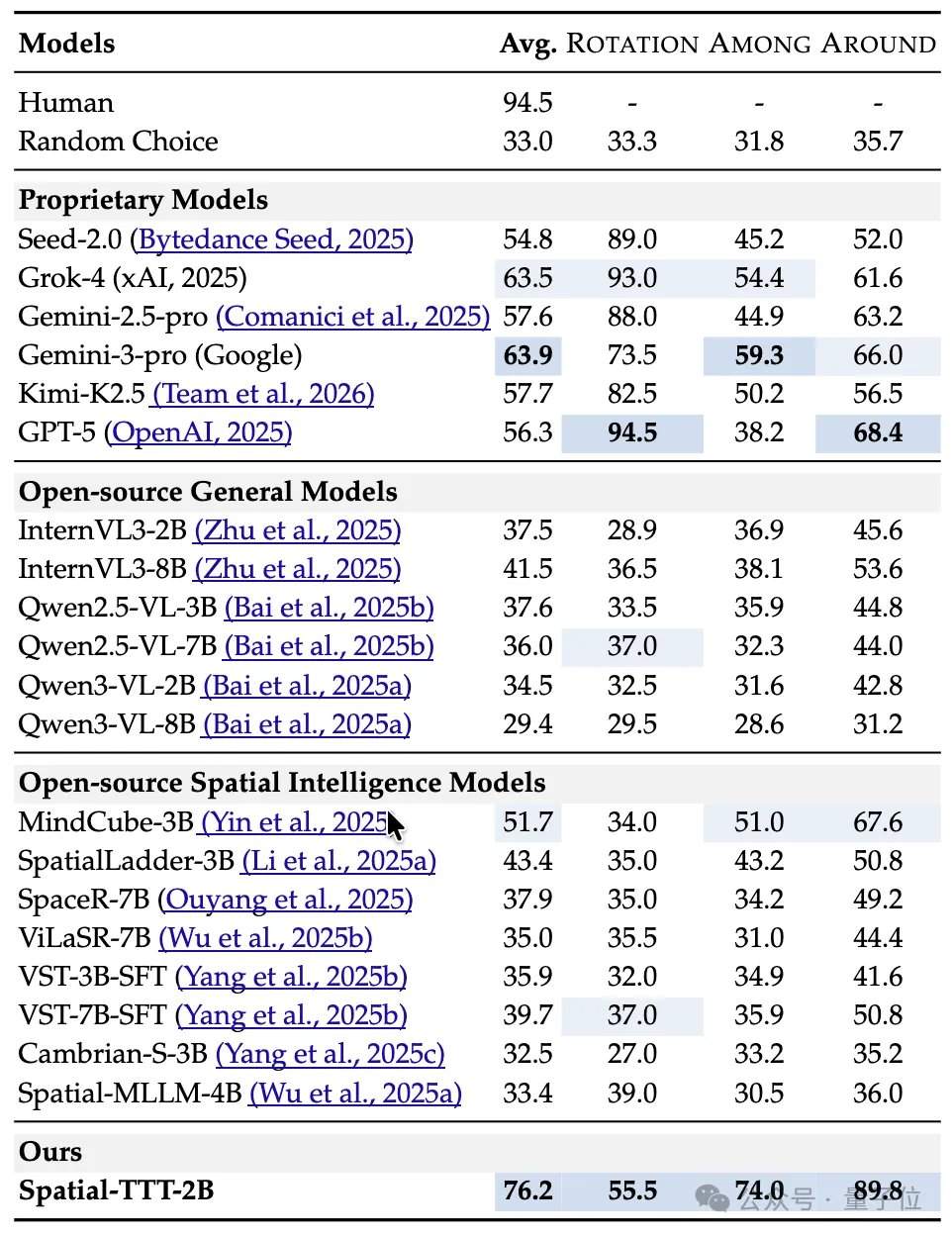
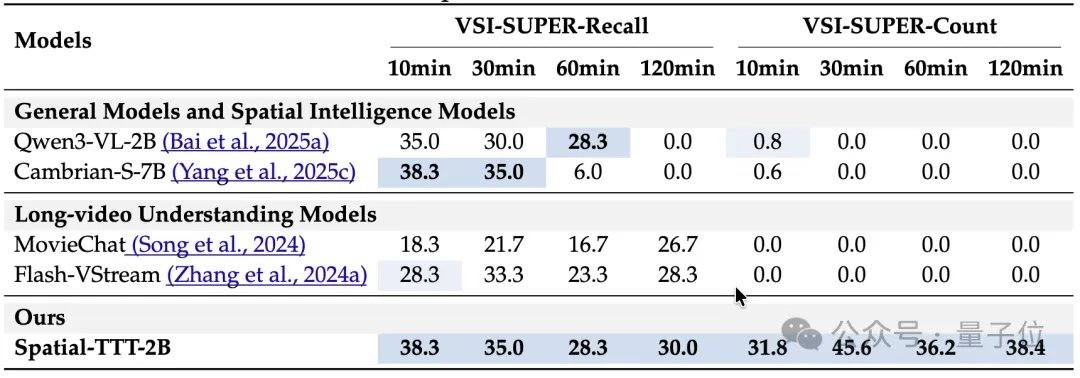
Что касается результатов экспериментов, Spatial-TTT с всего 2 миллиардами параметров продемонстрировал значительные преимущества на нескольких специализированных бенчмарках пространственного интеллекта. На VSI-Bench его средний балл достиг 64,4, превзойдя закрытые модели, такие как GPT-5 и Gemini-3-pro. На бенчмарке MindCube-Tiny, который проверяет более тонкое многовидовое пространственное рассуждение, Spatial-TTT достиг точности 76,2%, что на 12 процентных пунктов выше, чем у Gemini-3-pro (63,9%), и почти на 25 процентных пунктов выше, чем у репрезентативной открытой пространственной модели MindCube-3B (51,7%). В серии задач VSI-SUPER, проверяющих долговременную память, модель стабильно обрабатывала потоковое видео длительностью до 120 минут. В задаче VSI-SUPER-Count баллы Spatial-TTT на видео длительностью 10, 30, 60 и 120 минут составили 31,8, 45,6, 36,2 и 38,4 соответственно.
Анализ эффективности показал, что при настройке ввода из 1024 кадров пиковое использование видеопамяти Spatial-TTT-2B составляет 11,9 ГБ, а теоретический объем вычислений — 799,4 TFLOPs, что обеспечивает экономию более 40% видеопамяти и вычислительных ресурсов по сравнению с ведущими базовыми моделями в отрасли. Абляционные эксперименты дополнительно подтвердили, что повышение производительности обусловлено синергетическим эффектом между гибридной архитектурой, механизмом пространственного прогнозирования и плотными сигналами надзора. Конкретно: при удалении механизма пространственного прогнозирования средний балл VSI-Bench снизился с 64,4 до 62,1; при удалении плотного надзора за описанием сцены — до 61,3; при полном удалении гибридной архитектуры и использовании только чистой структуры TTT средний балл упал до 53,9.
Это исследование, принятое на ECCV 2026, предлагает новый технический путь для физических систем искусственного интеллекта, требующих длительной непрерывной работы. Позволяя модели непрерывно накапливать, корректировать и использовать пространственную информацию, будущие интеллектуальные агенты больше не будут сталкиваться с разрозненными кадрами, а смогут построить непрерывную, понятную внутреннюю модель мира, в которой они смогут действовать.
Ссылка на статью: https://arxiv.org/pdf/2603.12255
Домашняя страница проекта: https://liuff19.github.io/Spatial-TTT/
GitHub: https://github.com/THU-SI/Spatial-TTT/
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com