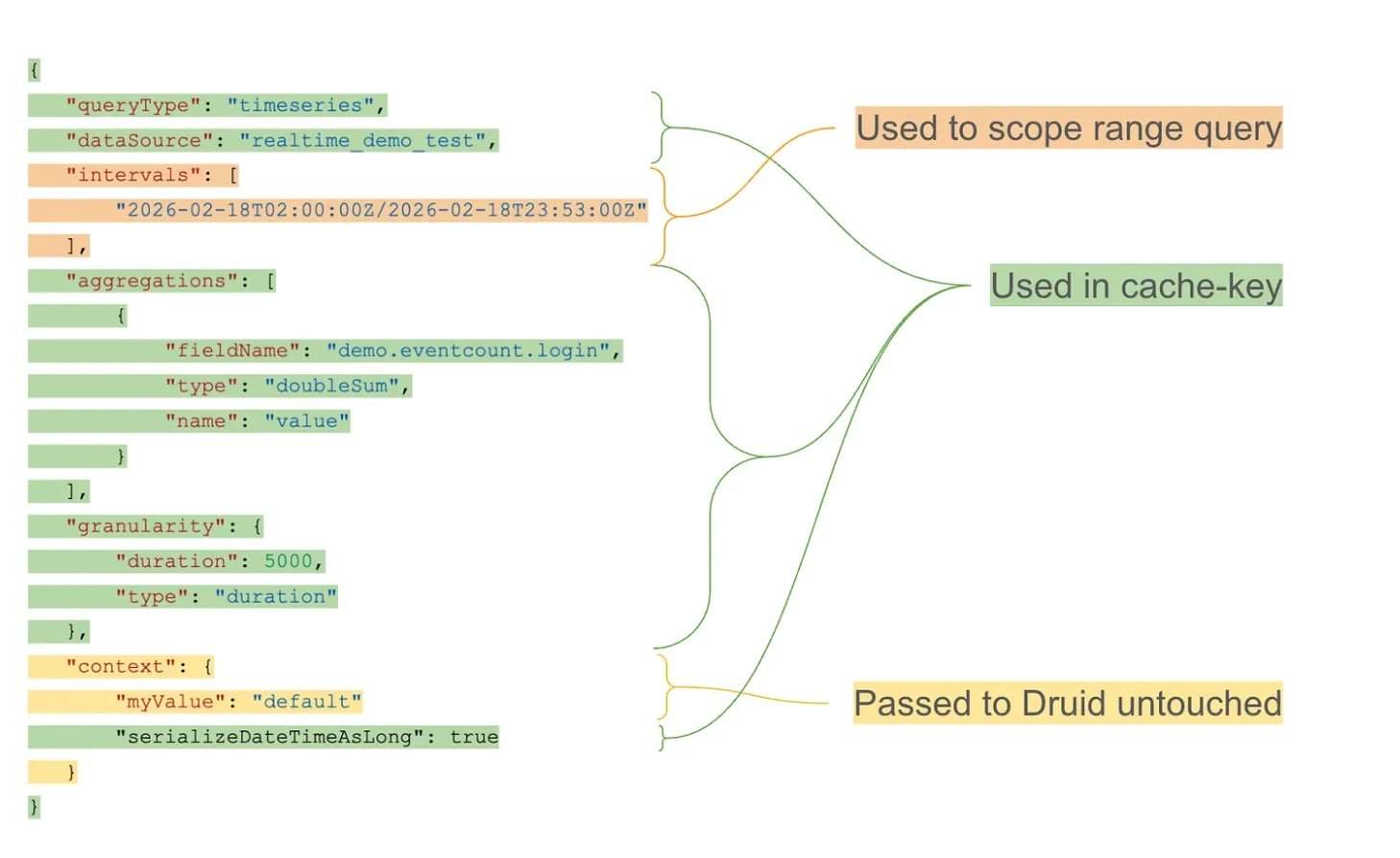
Репортаж от Wedoany,Компания Netflix (Нетфликс) оптимизировала эффективность запросов к базе данных Apache Druid, внедрив стратегию кэширования с учётом интервалов. В результате около 84% аналитических результатов поступает из кэша, нагрузка на запросы снизилась примерно на 33%, а время выполнения P90 улучшилось на 66%. Оптимизация в основном реализована через внешний прокси-слой кэширования, решая проблему избыточных вычислений и повторного сканирования больших наборов данных, вызванных незначительным смещением временных диапазонов при непрерывном обновлении запросов на панелях мониторинга с прокручивающимся окном.
В масштабах Netflix система реального времени обрабатывает триллионы строк данных, обеспечивая поддержку панелей мониторинга для мониторинга, экспериментов и операционных решений. Эти панели часто выполняют почти идентичные запросы, например, подсчёт уровня ошибок или показателей вовлечённости в скользящем временном окне. Эван Кинг, сооснователь Hello Interview, отмечал, что традиционное кэширование рассматривает повторяющиеся запросы с одинаковым намерением, но незначительно смещёнными временными границами, как разные запросы, что приводит к низкой частоте повторного использования кэша и повторным вычислениям в Apache Druid.
Метод Netflix разбивает результаты запросов на сегменты, выровненные по времени, чтобы их можно было повторно использовать в перекрывающихся запросах с прокручивающимся окном. Вместо кэширования полного вывода запроса система хранит промежуточные агрегации за фиксированные временные интервалы. Когда поступает новый запрос, кэшированные сегменты используются для относительно стабильной исторической части временного окна, а данные только за последний интервал пересчитываются из Druid и объединяются с кэшированными результатами.
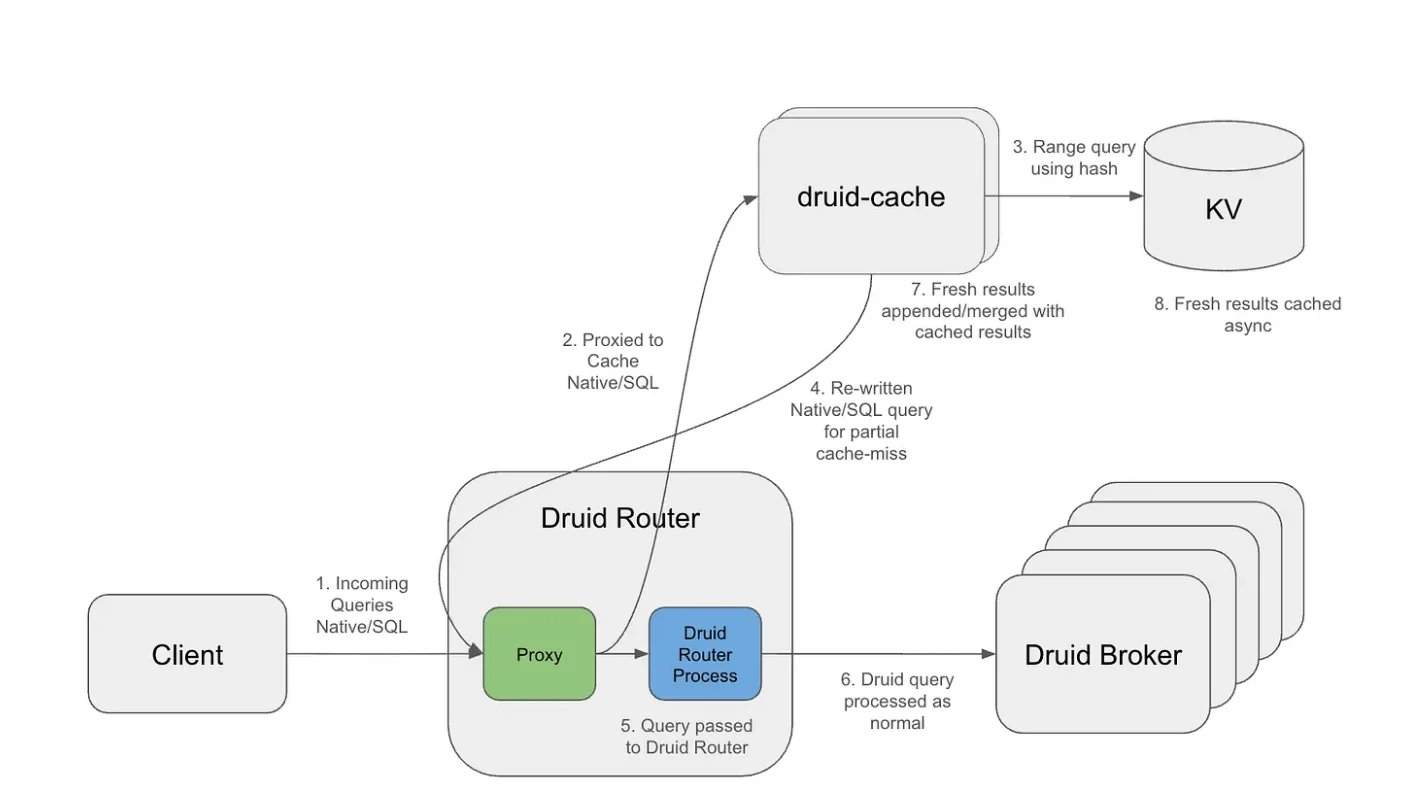
При рабочей нагрузке более 10 триллионов строк в Apache Druid повторяющиеся запросы с прокручивающимся окном стали основным узким местом. Слой кэширования, используя сегменты с выравниванием по гранулярности и стратегию экспоненциального TTL (времени жизни), обеспечивает долгосрочное кэширование исторических интервалов, сохраняя актуальность самых свежих данных. Архитектурно слой кэширования работает как внешний прокси, перехватывая входящие запросы, разделяя структуру запроса и временной интервал, генерируя повторно используемые ключи кэша. Сегменты кэша хранятся в распределённой системе ключ-значение, поддерживая независимое истечение срока действия и эффективный поиск.
Благодаря такой конструкции только последний интервал требует пересчёта, а исторические сегменты могут повторно использоваться в нескольких перекрывающихся запросах. В результате временной диапазон операций запросов, поступающих в Druid, значительно сокращается, сканируется меньше сегментов и обрабатывается меньше данных. При определённых рабочих нагрузках Netflix наблюдала уменьшение объёма результирующих байтов до 14 раз и значительное сокращение сканирования сегментов.
В настоящее время система развёрнута как экспериментальный слой и продолжает развиваться. Будущие работы включают расширение поддержки шаблонных SQL-запросов, используемых инструментами панелей мониторинга, чтобы уменьшить зависимость от нативных выражений запросов Druid. Netflix также изучает возможность прямой интеграции кэширования с учётом интервалов в Apache Druid, чтобы устранить необходимость во внешнем прокси-слое и повысить эффективность планирования запросов.
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com