

Репортаж от Wedoany,По мере замедления масштабирования плотности транзисторов, передовая упаковка становится основным направлением развития. Однако искусственный интеллект ускорители громоздки и требуют чрезвычайно высокой скорости межсоединений, что приводит к тому, что сама упаковка сталкивается с ограничениями. Круглые интерпозеры ограничивают размер упаковки и использование пластин, технология HBM4E удваивает количество контактов ввода-вывода при повышении скорости, а многокиловаттные упаковки делают традиционные архитектуры охлаждения неприемлемыми.
ECTC — ведущее отраслевое мероприятие по технологиям упаковки. Публикации этого года тесно связаны с коммерческими продуктами, готовящимися к выходу на рынок. Intel представила интеграцию EMIB-T, масштабирование размеров упаковки и дорожную карту будущего развития. Marvell продемонстрировала, как с помощью кастомного HBM можно удалить интерфейсную логику из ускорителя, одновременно сократив длину трассировки в упаковке. TSMC и Microsoft интегрируют охлаждающую жидкость непосредственно в кремний, в то время как Marvell и Lightmatter интегрируют оптические межсоединения в упаковку.
Данный обзор охватывает технологии ECTC 2026, которые с наибольшей вероятностью сформируют архитектуру AI-ускорителей в ближайшие годы.
Intel EMIB-T
Intel является крупнейшим корпоративным докладчиком на выставке ECTC. Основной акцент сделан на EMIB-T. Это чип EMIB следующего поколения, использующий технологию сквозных кремниевых переходов (TSV). После первоначального анонса Intel доработала архитектуру и дорожную карту, включив в них меньший шаг контактов, больший размер упаковки и функции моста. Их демонстрация показывает, что EMIB-T может найти применение в TPU v9 от Google и является наиболее надежной альтернативой платформе CoWoS от TSMC в области крупногабаритных AI-ускорителей.
Расширенный тестовый чип EMIB-T с содержанием кремния, вдвое превышающим размер фотошаблона. Изображения, полученные с помощью сканирующего электронного микроскопа (SEM) сверху, показывают шаг контактов 110, 55 и 36 мкм.

Intel уже верифицировала технологию EMIB-T на чипе, упакованном с использованием кремниевой пластины двойного размера фотошаблона, с шагом контактов 36/35 мкм. По сравнению с шагом 45 мкм, используемым в упаковке Granite Rapids, плотность контактов увеличена на 65%. Granite Rapids-AP — это крупная упаковка размером 70 мм × 105 мм, площадь которой немного меньше 9 фотошаблонов. В настоящее время верификация для шага контактов 36/35 мкм расширяется на упаковку с кремниевой пластиной размером 4,5 фотошаблона, с целью завершения сертификации к концу 2026 года.

Следующий шаг по уменьшению шага также находится в разработке: Intel тестирует шаг контактов 25 мкм, основанный на чипе, состоящем из двух кремниевых кристаллов размером 1 фотошаблон, соединенных одним мостом EMIB-T размером 3 мм × 18 мм.
Дальнейшее уменьшение размеров станет более сложной задачей. При шаге менее 25 мкм объем припоя в каждом шариковом выводе становится очень малым. Значительно возрастает вероятность коротких замыканий, обрывов и потери выхода годных в процессе сборки. EMIB-T может продолжать уменьшать размеры, но ограничивающий фактор смещается с плотности трассировки моста на формирование шариковых выводов, точность позиционирования и выход годных при сборке.
Intel также продемонстрировала предельные размеры упаковки EMIB-T. Хотя возможна упаковка размером с полную панель, Intel рассматривает упаковку размером с четверть панели в качестве практической цели. Был показан тестовый образец размером 240 мм × 240 мм, площадь которого примерно эквивалентна 67 фотошаблонам. Однако образец на стенде демонстрировал значительное коробление. При таком размере мост является лишь частью проблемы. Обработка подложки, коробление, точность совмещения слоев и формирование рисунка на уровне панели становятся первостепенными ограничивающими факторами. Intel также оценивает передовые технологии литографии для обеспечения достаточной точности совмещения слоев на этих крупноформатных подложках при размерах в четверть панели или даже полной панели.
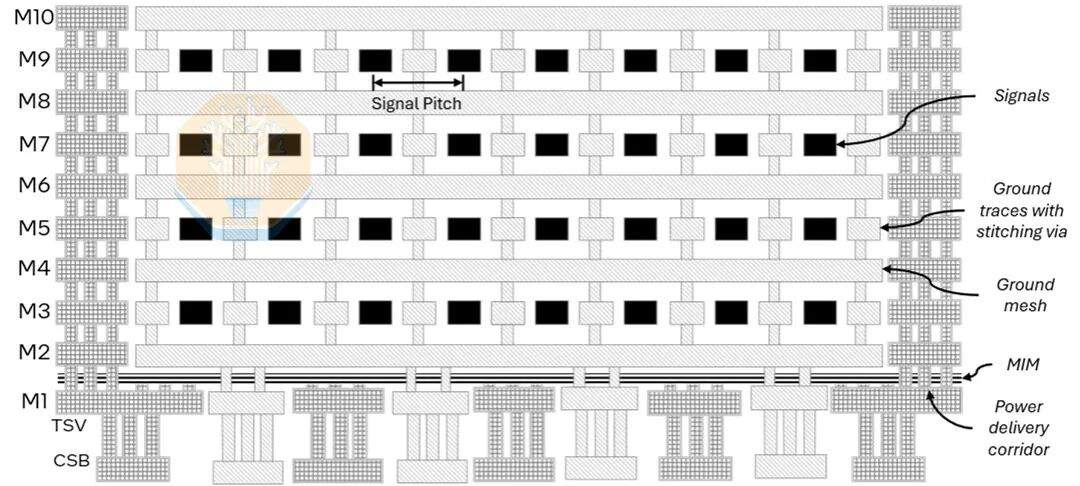
Хотя шаг контактов и размер упаковки важны, схемотехника моста не менее критична. EMIB-T значительно сложнее, чем EMIB, используемый в текущих продуктах. Он добавляет TSV, большее количество металлических слоев, сеть питания и слой MIM-конденсаторов, что позволяет мостовой схеме одновременно передавать высокоплотные сигналы и обеспечивать вертикальное питание. Intel продемонстрировала поперечное сечение, содержащее 10 металлических слоев (включая 4 слоя трассировки), а также MIM-конденсатор между M1 и M2. Intel особо отметила улучшения для HBM4E.
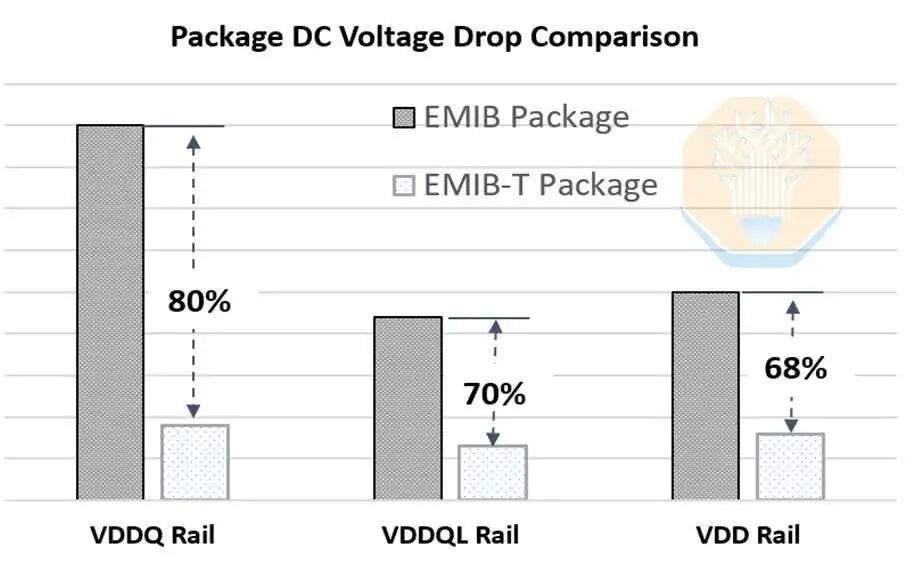
Буква "T" в названии EMIB-T означает TSV (сквозные кремниевые переходы). Их функция — подача питания. В традиционном EMIB питание в областях, не занятых мостом, передается вертикально через подложку, в то время как питание вблизи области моста должно распространяться латерально через трассировку упаковки и чипа. Используя TSV в области моста, питание может передаваться непосредственно через мост, что значительно сокращает путь тока. Intel утверждает, что использование этих TSV позволяет снизить падение постоянного напряжения на 68–80%.
Сложность HBM4E заключается в том, что межсоединения должны одновременно повышать плотность сигналов и способность передачи питания. HBM4 имеет вдвое больше контактов, чем HBM3, и PHY требует дополнительных шин питания, таких как VDDQ и VDDQL. Эти шины питания занимают часть пространства для трассировки сигналов, тем самым повышая плотность сигналов на оставшейся площади.
Для решения этой проблемы Intel не использует одинаковую трассировку для всех каналов HBM. Самые длинные сигнальные пути размещаются на слоях с более простой трассировкой. На слое M9 только около 28% длины самых длинных каналов проходят через область с наиболее плотной трассировкой, в то время как на нижних слоях, таких как M3, этот показатель возрастает примерно до 84%, но длина этих каналов меньше. Это позволяет избежать ситуации, когда перекрестные помехи и потери вставки в основном определяются областями с наихудшей трассировкой.
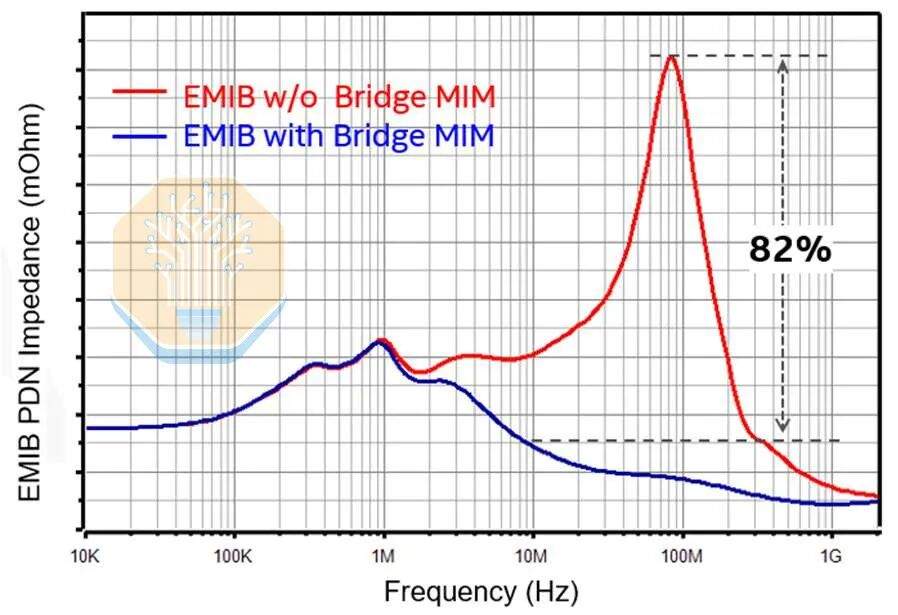
Передача питания также была перенесена на слой моста. EMIB-M ввел конденсаторы металл-изолятор-металл (MIM) между M1 и M2, а EMIB-T улучшил эту конструкцию. Intel сообщила о плотности емкости 500 нФ/мм², что примерно соответствует MIM-конденсаторам техпроцесса Intel 18A. Intel утверждает, что по сравнению с упаковкой EMIB-T без мостовых MIM-конденсаторов, эти мостовые конденсаторы снижают импеданс сети распределения питания (PDN) по переменному току более чем на 82%.
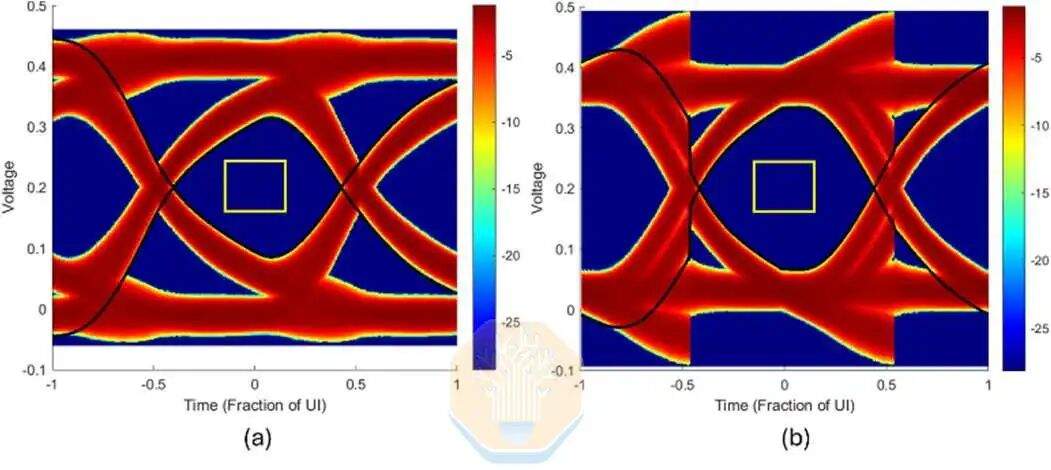
Intel также провела симуляцию EMIB-T с HBM4E. При скорости 12 Гбит/с без использования эквализации на приеме ширина глазковой диаграммы UI Intel составила около 67%. При использовании однокаскадного DFE (решающей обратной связи) это значение увеличилось примерно до 72,5%. DFE — это схема на приемной стороне, которая снижает влияние предыдущих битов после прохождения сигнала через канал упаковки.
Intel также моделировала более высокие скорости передачи: 12,8 Гбит/с, 14 Гбит/с и 16 Гбит/с. На всех тестируемых скоростях ширина глазковой диаграммы UI оставалась выше 60%, при незначительном снижении емкости контактной площадки.
Дорожная карта Intel по EMIB выходит за рамки пассивных мостовых технологий, включающих только трассировку и конденсаторы. Будущие версии будут включать мостовые MIM-конденсаторы более высокой плотности, мостовые чипы большего размера с высоким аспектным соотношением, шаг контактов менее 25 мкм, активные мосты и интеграцию регуляторов напряжения непосредственно в чип EMIB. Intel также представила концепцию встроенных в подложку глубокотравленных конденсаторов (DTC) и конденсаторов eMIM-T с плотностью >2500 нФ/мм², встроенных под подложкой, хотя эти технологии еще не были замечены в отгружаемых продуктах EMIB.
EMIB-T по-прежнему отстает от платформы CoWoS от TSMC по ряду параметров. TSMC уже реализовала интеграцию DTC/eDTC и продвинулась дальше в области интеграции регуляторов напряжения и активных локальных кремниевых межсоединений (LSI). EMIB-T сокращает разрыв, но Intel все еще догоняет экосистему, которая работает в массовом масштабе уже много лет.
Кастомный HBM от Marvell
На Дне отраслевых аналитиков Marvell в 2024 году компания объявила о создании кастомного HBM. В то время это было лишь расплывчатое заявление без технических деталей. Дизайн HBM всегда был сосредоточен на совместимости с JEDEC: стандартные стеки DRAM от поставщиков памяти, стандартный PHY HBM на ускорителе и фиксированный широкий интерфейс между ними. На конференции Hot Chips 2025 Marvell показала топологию кастомного базового кристалла.

На конференции ECTC Marvell наконец предоставила детали упаковки для кастомного HBM4E.
Спецификация JEDEC фиксирует интерфейс между стеком HBM и хост-устройством. Это обеспечивает совместимость: HBM любого производителя памяти может быть сопряжен с любым совместимым хостом. Однако это вредит энергопотреблению, производительности и площади. Хост-ASIC должен реализовывать стандартный PHY HBM с стандартизированной разводкой контактных площадок и правилами разводки, трассируя очень широкий параллельный интерфейс. По мере увеличения размера упаковки и повышения скорости HBM эта фиксированная граница усложняет оптимизацию береговой линии, плотности трассировки, подачи питания и целостности сигналов.

Технология кастомного HBM не требует никаких изменений в кристаллах DRAM. Вместо этого изготавливается кастомный базовый кристалл с оптимизированным межкристальным интерфейсом с использованием передового логического техпроцесса. Этот кастомный базовый кристалл может интегрировать контроллер HBM, функции управления и мониторинга, кастомную логику и расширенные интерфейсы.

Marvell утверждает, что это позволяет сократить занимаемую площадь хост-ASIC для PHY HBM и связанной логики примерно на 60%, что напрямую высвобождает больше места для вычислений, кэша или ввода-вывода. Этот кастомный интерфейс переносит большую часть интерфейса со стороны памяти в базовый кристалл HBM.
В примере Marvell используется 1024 канала со скоростью 32 Гбит/с, что обеспечивает пропускную способность 4,1 ТБ/с, что эквивалентно интерфейсу JEDEC HBM4(E) с разрядностью 2048 бит и скоростью 16 Гбит/с.
Трассировка упаковки также упрощается: кастомный интерфейс сокращает длину канала интерпозера с 6,5 мм до 1,5 мм, что позволяет Marvell увеличить пропускную способность, сохраняя те же 9 слоев трассировки и ширину/шаг проводников (L/S) 2/2 мкм.
В своем примере Marvell использует органический интерпозер с перераспределительным слоем (RDL) вместо кремния, что снижает стоимость упаковки. Органический RDL имеет гораздо меньшую ширину/шаг проводников по сравнению с кремниевым интерпозером в CoWoS-S или кремниевыми мостами в CoWoS-L и EMIB-T, что усложняет трассировку. Marvell полагается на кастомное экранирование и схемы трассировки в различных частях для максимизации плотности пропускной способности при контроле перекрестных помех.

На конференции GTC компания Nvidia объявила, что Feynman будет использовать кастомный HBM. Мотивы Nvidia, вероятно, схожи с Marvell: более высокая пропускная способность, меньшее энергопотребление и меньшая площадь чипа ускорителя, занимаемая HBM. Около 16% площади кристалла GPU Rubin используется для логики и PHY, связанных с HBM. Кастомный HBM позволит Nvidia перенести большую часть этой нагрузки на базовый кристалл HBM.
Кастомный HBM также поддерживает расширенные интерфейсы за пределами стандартных каналов HBM. Базовый кристалл может выступать в роли вспомогательного контроллера памяти и распределять трафик на дополнительную память, а не пропускать весь трафик памяти через ограниченные каналы на краю кристалла ускорителя. Эта дополнительная память может быть LPDDR с большей емкостью и меньшей пропускной способностью или даже вторым уровнем HBM. Это позволяет ускорителю расширять объем памяти, не занимая ценные каналы на краю кристалла, необходимые для внешнего ввода-вывода. Это особенно важно для готовящихся к выпуску GPU AMD MI450 и будущих MI500, которые будут поддерживать LPDDR для увеличения объема памяти.
Интерпозер HBM от Samsung
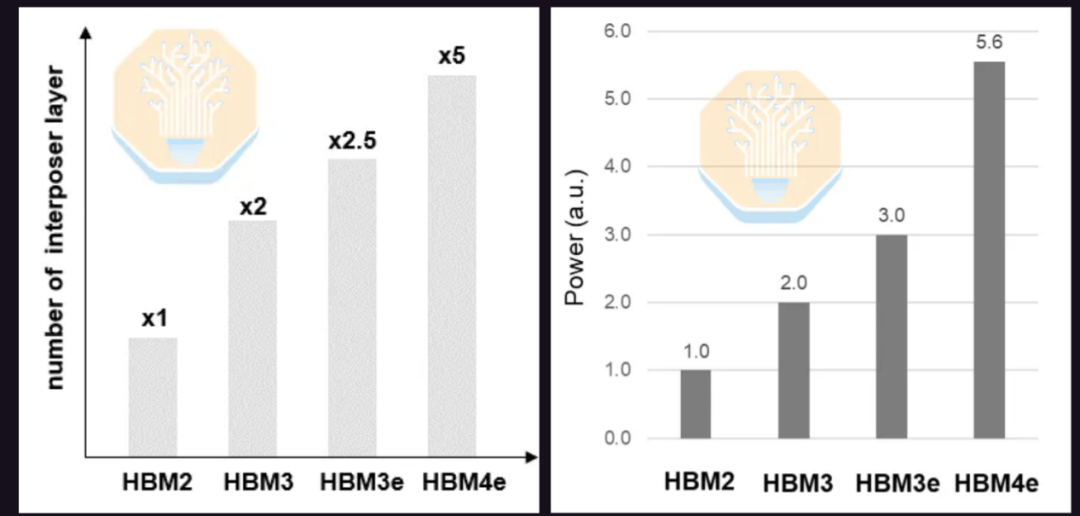
Samsung также продемонстрировала свое решение на основе интерпозера для HBM4E. HBM4E увеличивает скорость передачи данных до 12 Гбит/с и выше, а также удваивает количество контактов ввода-вывода, что усложняет трассировку. HBM4E может потребовать вдвое больше слоев интерпозера, чем HBM3E, и в пять раз больше, чем HBM2. Ожидается, что энергопотребление также увеличится на 86% по сравнению с HBM3E и в 5,6 раза по сравнению с HBM2 из-за увеличения количества контактов ввода-вывода и повышения скорости передачи данных.
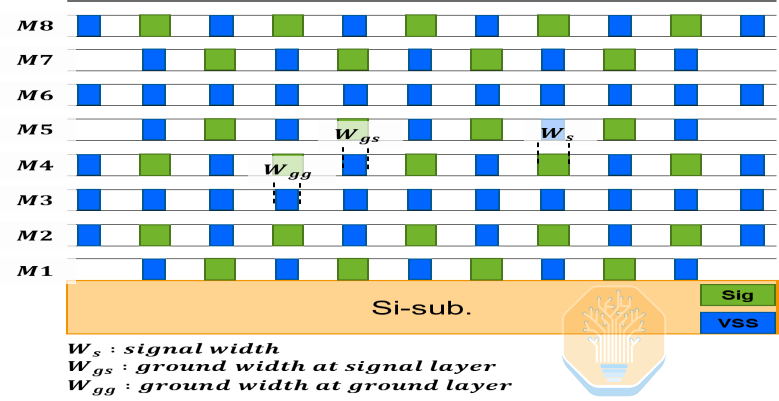
Samsung предложила 8-слойный кремниевый интерпозер, который, как утверждается, на 20% уменьшает количество слоев по сравнению с прогнозируемыми требованиями. Этот интерпозер использует повторяющуюся структуру с чередованием двух сигнальных и одного земляного проводника для экранирования высокоскоростных сигналов, при этом 75% слоев используются для трассировки сигналов.
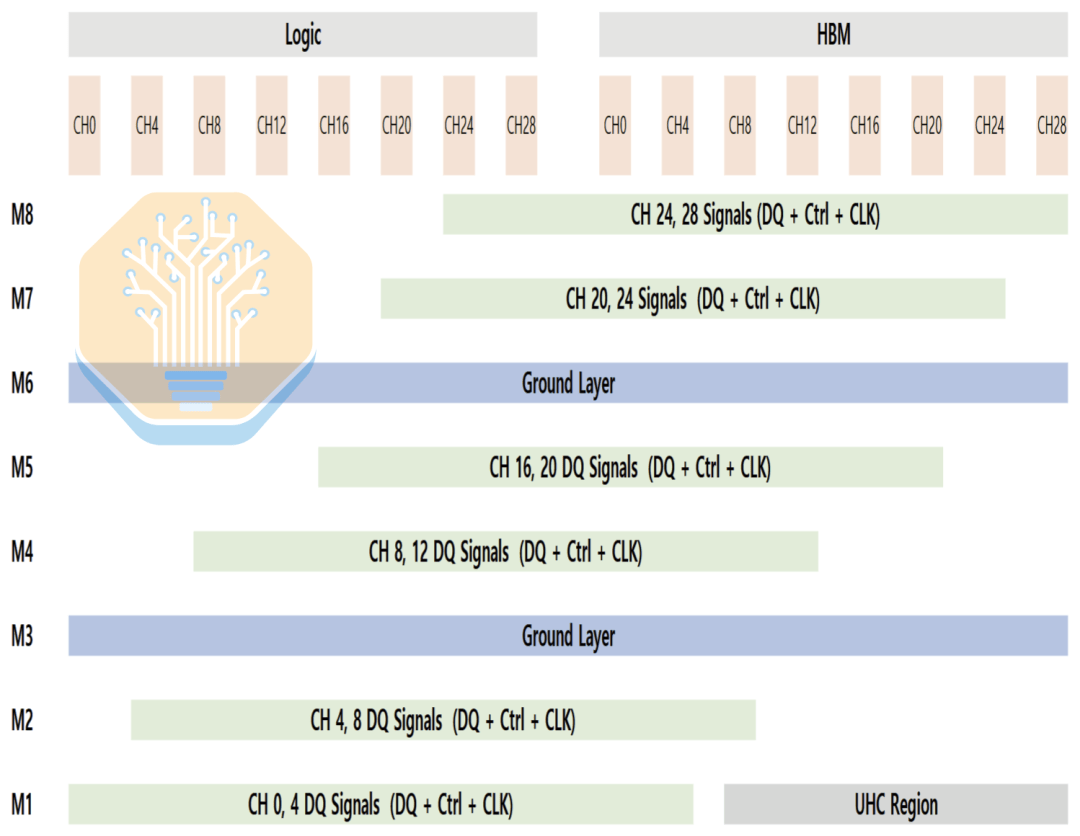
Еще одной ключевой особенностью интерпозера является конденсатор сверхвысокой плотности (UHC). Samsung не уточняет конкретную структуру конденсатора, но они, вероятно, аналогичны MIM-конденсаторам Intel EMIB-T или DTC-конденсаторам TSMC CoWoS. Конденсаторы UHC могут быть размещены только на слое M1, который также в основном используется для трассировки сигналов, поэтому доступная площадь ограничена.
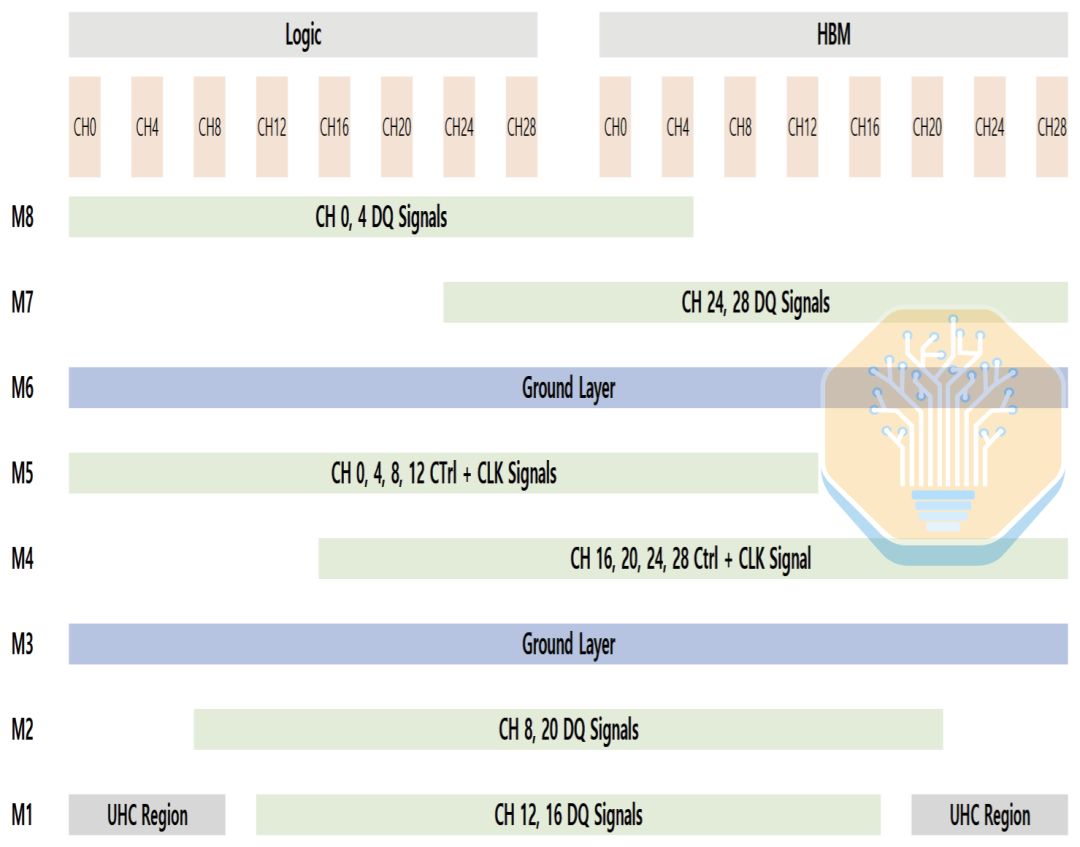
Если трассировка несбалансирована, конденсаторы смещаются к одной стороне интерфейса, что приводит к неравномерной производительности сети распределения питания (PDN) между логической стороной и стороной HBM. Компоновка Samsung перераспределяет трассировку между слоем M1 и другими слоями, что позволяет конденсаторам UHC распределяться более равномерно по всему интерфейсу. Это снижает импеданс PDN и шум по напряжению, сохраняя при этом плотность трассировки на управляемом уровне.
Тепловые характеристики гибридного соединения HBM от Samsung
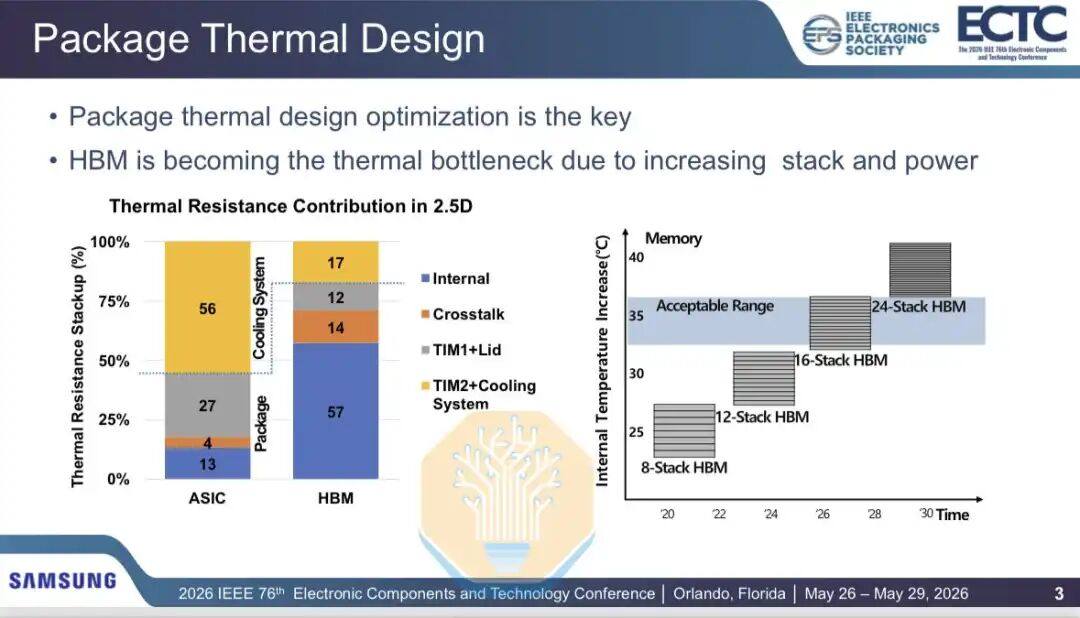
Samsung также обсудила тепловые проблемы HBM, особенно в отношении технологии гибридного соединения. Стеки HBM становятся все более многослойными и быстрыми, а логические чипы под ними потребляют все больше энергии. Для 16-слойного HBM тепловое сопротивление еще приемлемо, но по мере перехода к 20- и 24-слойным HBM в будущих поколениях потребуются новые решения.
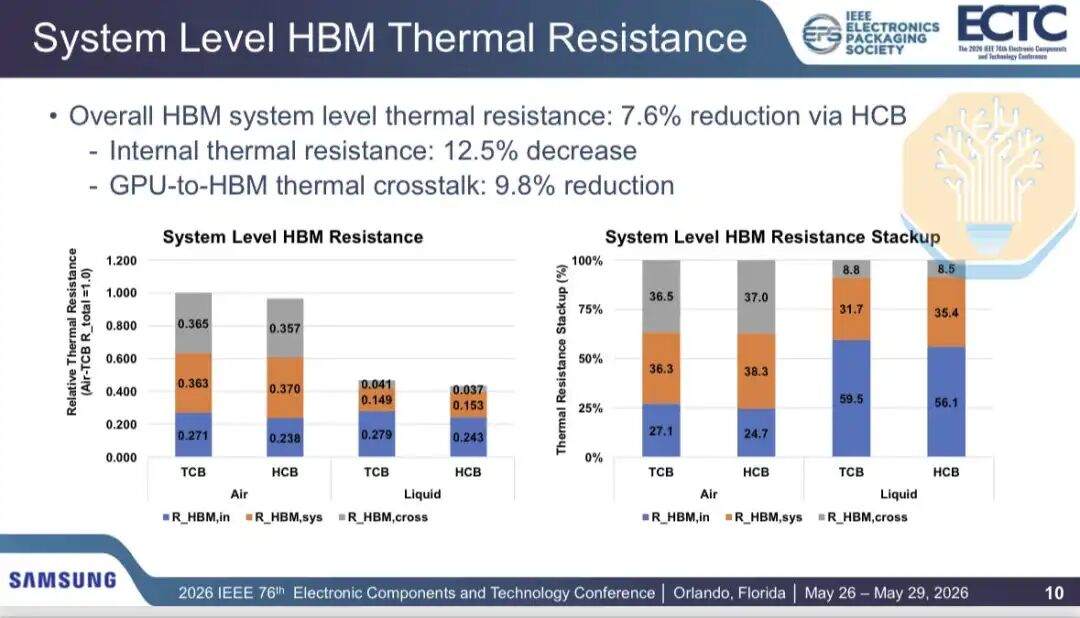
Samsung сравнила тепловые характеристики HBM при использовании термокомпрессионного соединения (TCB) и гибридного медного соединения (HCB) в 2,5D упаковке GPU (содержащей 2 чипа GPU и 8 стеков HBM, аналогично архитектуре Nvidia Blackwell). Результаты показывают, что воздушное охлаждение снижает внутреннее тепловое сопротивление HBM на 12,2%, а жидкостное — на 12,9%. Общее тепловое сопротивление HBM снижается на 3,5% при воздушном охлаждении и на 7,7% при жидкостном.
Поскольку HCB воздействует только на часть тепловой сети, улучшения неравномерны. Samsung разделила тепловые пути на внутреннее тепловое сопротивление, системное тепловое сопротивление и перекрестные помехи от GPU к HBM. Внутреннее тепловое сопротивление и перекрестные помехи снизились примерно на 12,5% и 9,8% соответственно, но системное тепловое сопротивление, включающее термоинтерфейсный материал и радиатор, увеличилось примерно на 2,3%.
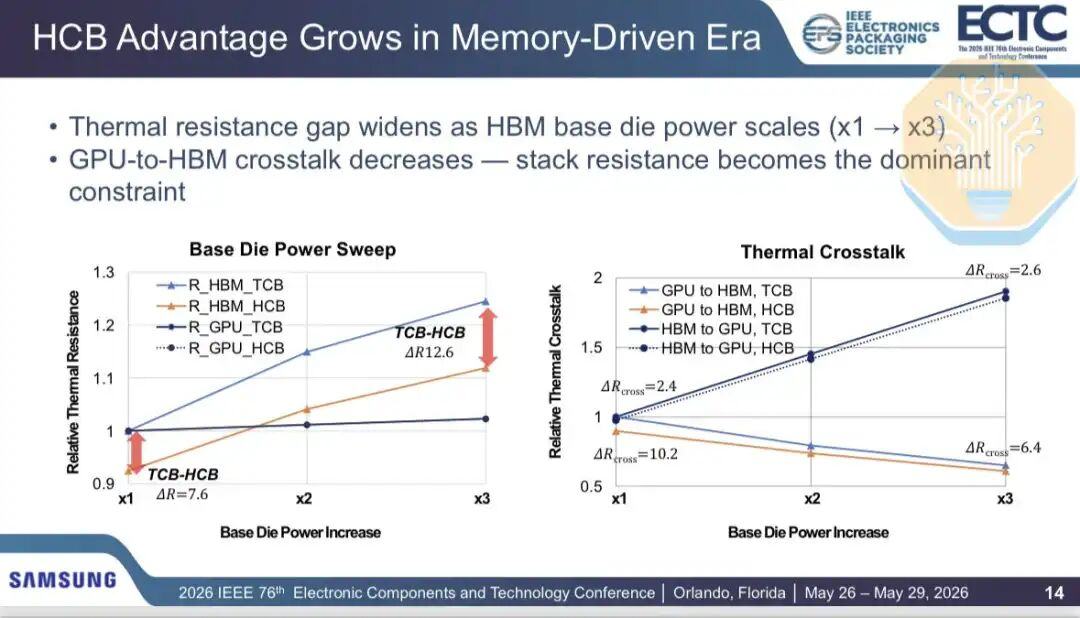
По мере того как большая мощность переходит на базовый кристалл HBM (например, в задачах с интенсивным использованием памяти), узкое место в отводе тепла смещается. Это особенно важно для кастомного HBM, где контроллер памяти и больше логических схем интегрированы в базовый кристалл. Доля перекрестных помех от GPU к HBM в общем тепловом сопротивлении снижается с 13% при удвоении энергопотребления базового кристалла до 5% при его утроении.
Samsung заявляет, что использование технологии HCB позволяет повысить температуру входящего воздуха или увеличить мощность упаковки. По оценкам компании, при использовании HCB температура входящего воздуха может быть повышена на 1–2 °C при сохранении мощности упаковки, или мощность упаковки может быть увеличена примерно на 4% при сохранении температуры. Samsung также оценивает снижение тепловой мощности примерно на 7%.
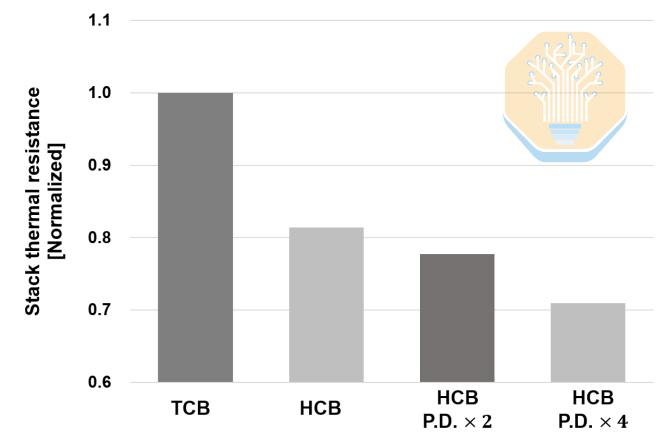
Samsung также отдельно изучила влияние HCB на уровне стека. Улучшения здесь более значительны: базовый HCB снижает тепловое сопротивление стека примерно на 19% по сравнению с TCB. Увеличение количества контактных площадок HCB при двукратном увеличении плотности площадок приводит к снижению теплового сопротивления на 22,3%, а при четырехкратном увеличении — на 29,1%.
Микрофлюидное охлаждение
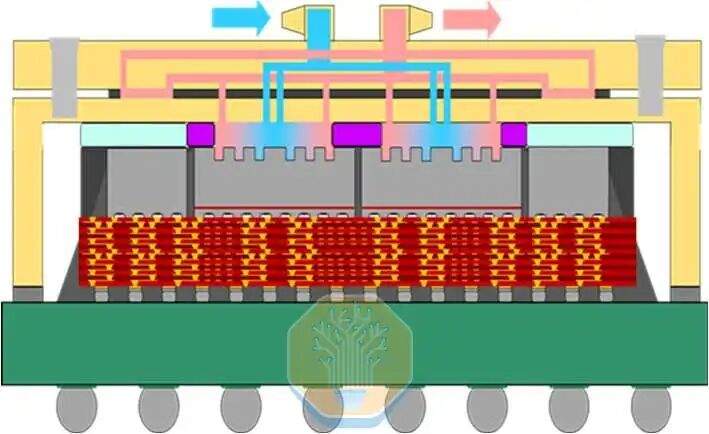
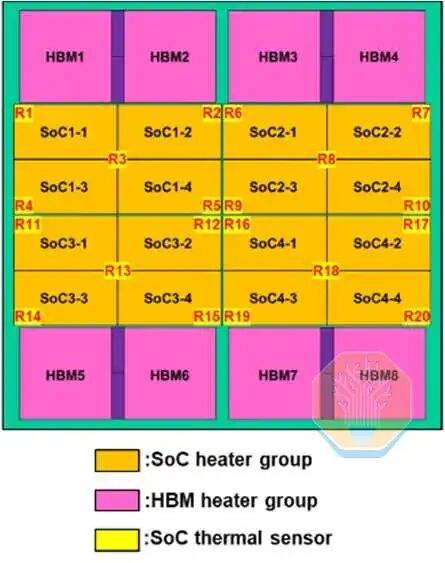
TSMC продемонстрировала технологию прямого охлаждения кремния на чипе CoWoS-R, используемом в крупном тестовом стенде, подобном GPU. CoWoS-R отличается от CoWoS-S использованием органических материалов вместо кремниевого интерпозера. CoWoS-R был выбран из-за лучшей устойчивости к короблению и технологической совместимости. Тестовый стенд использует интерпозер размером 3,3 фотошаблона, содержащий 4 чипа SoC и 8 стеков HBM. Каждый чип SoC состоит из 4 групп нагревателей SoC, которые вместе покрывают примерно половину площади интерпозера.
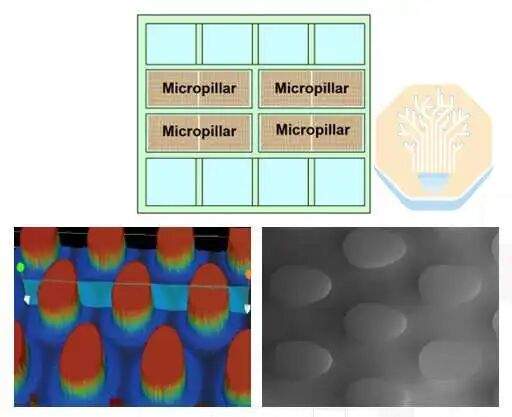
TSMC сравнила три варианта: традиционную упаковку с крышкой и холодной плитой, упаковку без крышки с холодной плитой и свою конструкцию с прямым охлаждением кремния с использованием микростолбиков. Варианты с крышкой и без нее по-прежнему используют традиционную холодную плиту и термоинтерфейсный материал (TIM). Последний вариант предполагает формирование микростолбиков непосредственно на обратной стороне чипа SoC.
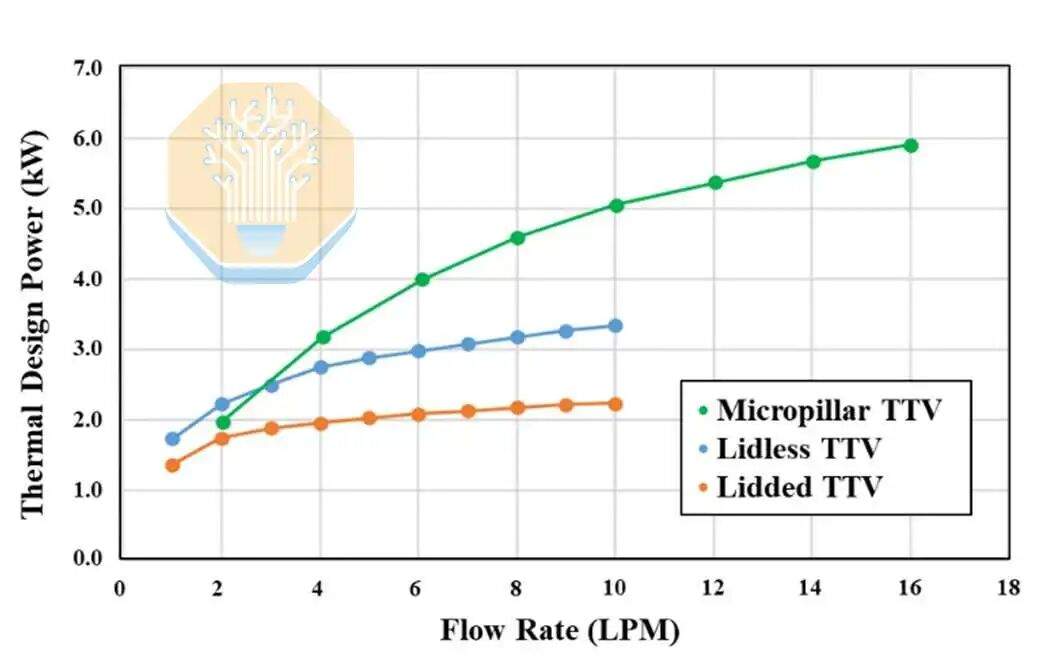
При обычном охлаждении и скорости потока 1–2 литра в минуту (LPM) упаковка с крышкой рассеивает 1,9–2,3 кВт, а упаковка без крышки — 2,5–3,0 кВт, используя деионизированную воду с температурой 40 °C. Оба варианта достигают насыщения при скорости потока выше 4 LPM, поскольку термоинтерфейсный материал (TIM) становится узким местом.
Тестовый стенд с микростолбиками показал результаты, сопоставимые с упаковкой без крышки при скорости потока 2 LPM, а затем превзошел их при более высоких скоростях потока, достигнув 4 кВт при 4 LPM и 5,3 кВт при 8 LPM. TSMC сообщает о равномерном рассеивании мощности более 5 кВт по всему тестовому стенду. Структура с микростолбиками приближает жидкий хладагент к источнику тепла, что способствует улучшению теплоотвода.
Однако структура с микростолбиками не лишена недостатков. TSMC должна формировать микростолбики после завершения процесса сборки чипа в упаковку (CoW), избегая при этом повреждения структуры CoWoS-R, и разработать новые герметизирующие материалы, чтобы обеспечить герметичность хладагента при короблении упаковки и несоответствии коэффициентов теплового расширения. Тестовые образцы прошли испытания на чувствительность к влаге уровня 4 (MSL4) без утечек гелия или расслоения герметика.
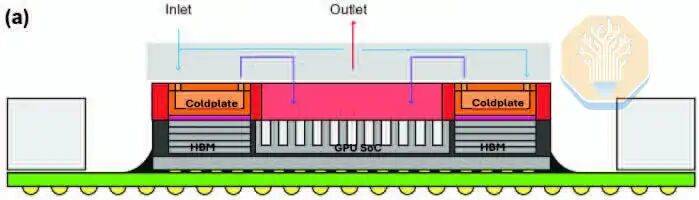
Решение Microsoft по охлаждению отличается от решения TSMC структурой охлаждения. TSMC использует кремниевые микростолбики, в то время как Microsoft использует прямые микроканалы, вытравленные в кремнии GPU. Microsoft не использовала тепловой тестовый стенд, а проводила испытания непосредственно на GPU Nvidia GH200. Это, возможно, позволило Microsoft более точно зафиксировать реальное распределение тепла и горячие точки. Microsoft тестировала GPU с различными рабочими нагрузками, такими как HPCG и HPL, каждая из которых имеет различные характеристики вычислительной нагрузки и нагрузки на память.
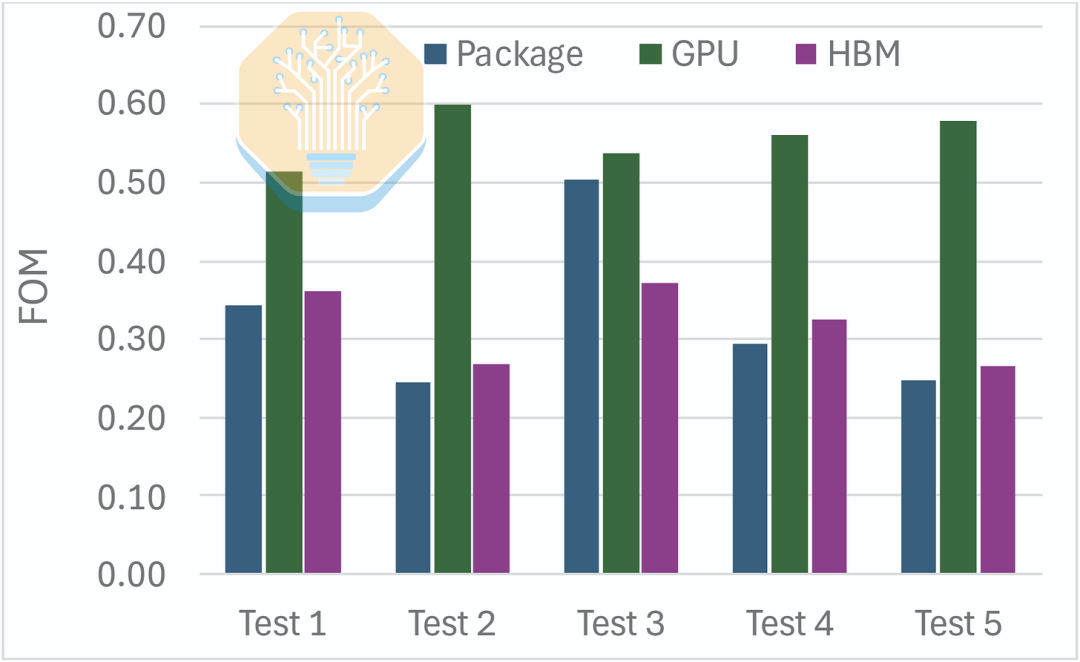
При этих рабочих нагрузках Microsoft сообщила о снижении теплового сопротивления от перехода к входу GPU на 51–60% при скорости потока 1 LPM. Улучшения для HBM были скромнее — 27–37%, поскольку он по-прежнему охлаждается через холодную плиту и термоинтерфейсный материал. В целом, это привело к снижению теплового сопротивления упаковки на 50%.
Microsoft также представила некоторые предварительные данные по надежности. Хотя тепловые характеристики важны, развертывание в центрах обработки данных также требует высокой надежности и низкого времени простоя. За 6 месяцев Microsoft зафиксировала только 9 потенциальных событий засорения примерно за 4370 наблюдений. Частота засорений со временем снижалась, что указывает на нестабильность на начальном этапе установки с последующим переходом к более стабильной работе. Даже через 6 месяцев в микроканалах не было обнаружено измеримой коррозии кремния. На уровне узла GH200 успешно прошел повторяющиеся эталонные тесты в течение 3 недель, после чего непрерывно работал в течение 1 недели при стабильной мощности упаковки. Microsoft продолжает тестирование среднего времени наработки на отказ (MTBF) и доступности на уровне кластера.










