Репортаж от Wedoany,Опубликована сверхскоростная аудиомодель AudioX-Turbo: 4 шага вывода, генерация 10-секундного аудио за 0,24 секунды. Разработанная компанией Noiz AI совместно с Гонконгским университетом науки и технологии и Университетом Цинхуа, модель поддерживает мультимодальный ввод, включая текст, видео и изображения. Благодаря технологии дистилляции распределения и состязательной дистилляции процесс генерации традиционных диффузионных моделей, требующий от 50 до 200 шагов, был сжат до 4 шагов, что снизило количество прямых проходов модели примерно в 25 раз. На одной видеокарте RTX 4090 генерация 10-секундного аудио занимает всего 0,24 секунды, а коэффициент реального времени составляет всего 0,02, что открывает возможности для интерактивного аудио в реальном времени.
Существующие основные аудиомодели, такие как MMAudio и Stable Audio Open, полагаются на технологии диффузии или потокового согласования и обычно требуют десятков или сотен итераций. AudioX-Turbo использует нативный мультимодальный диффузионный трансформер (MMDiT) в качестве основы и, в сочетании с модулем MAF, обучает модель с нуля с 2,7 миллиарда параметров. В рамках потокового согласования исследовательская группа внедрила дистилляцию распределения (DMD) и состязательную дистилляцию, сжав модель до 4 шагов, а также устранила дополнительные затраты NFE с помощью дистилляции CFG. Благодаря диффузионному дискриминатору студенческая модель превзошла учительскую модель со 100 шагами по некоторым показателям производительности.
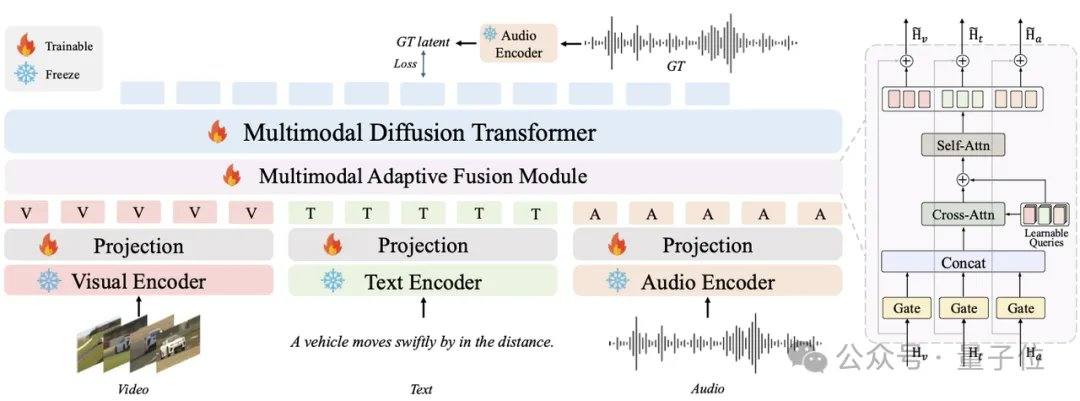
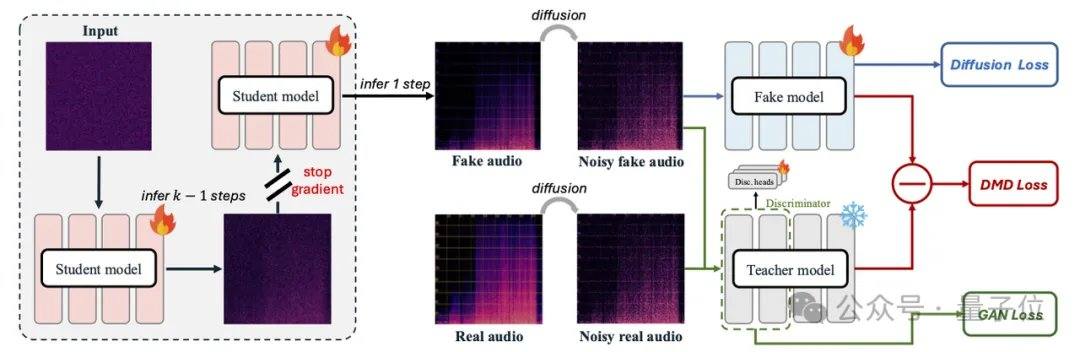
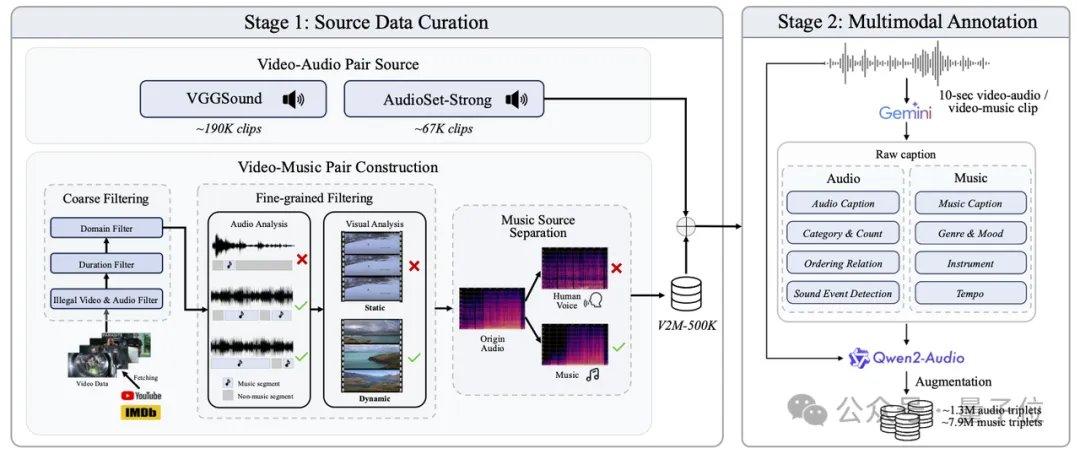
AudioX-Turbo также решает проблему точного управления аудиомоделями. Исследовательская группа отмечает, что многие предыдущие модели не могли точно контролировать временные метки, что было связано с размытыми текстовыми метками в обучающих данных. Для решения этой проблемы Noiz AI и команда Гонконгского университета науки и технологии специально создали сверхбольшой мультимодальный аудионабор данных IF-caps-Pro общим объемом около 9,2 миллиона. Команда применила схему «каскадной разметки с помощью больших моделей»: сначала были созданы большие объемы высококачественных пар видео-аудио, затем с помощью модели Gemini 2.5 Pro были сгенерированы структурированные шаблоны с временными метками, инструментами и количеством событий, а затем с помощью Qwen2-Audio была проведена масштабная расшифровка, превратив данные из «размытых аннотаций» в «сценарии с точной временной шкалой».
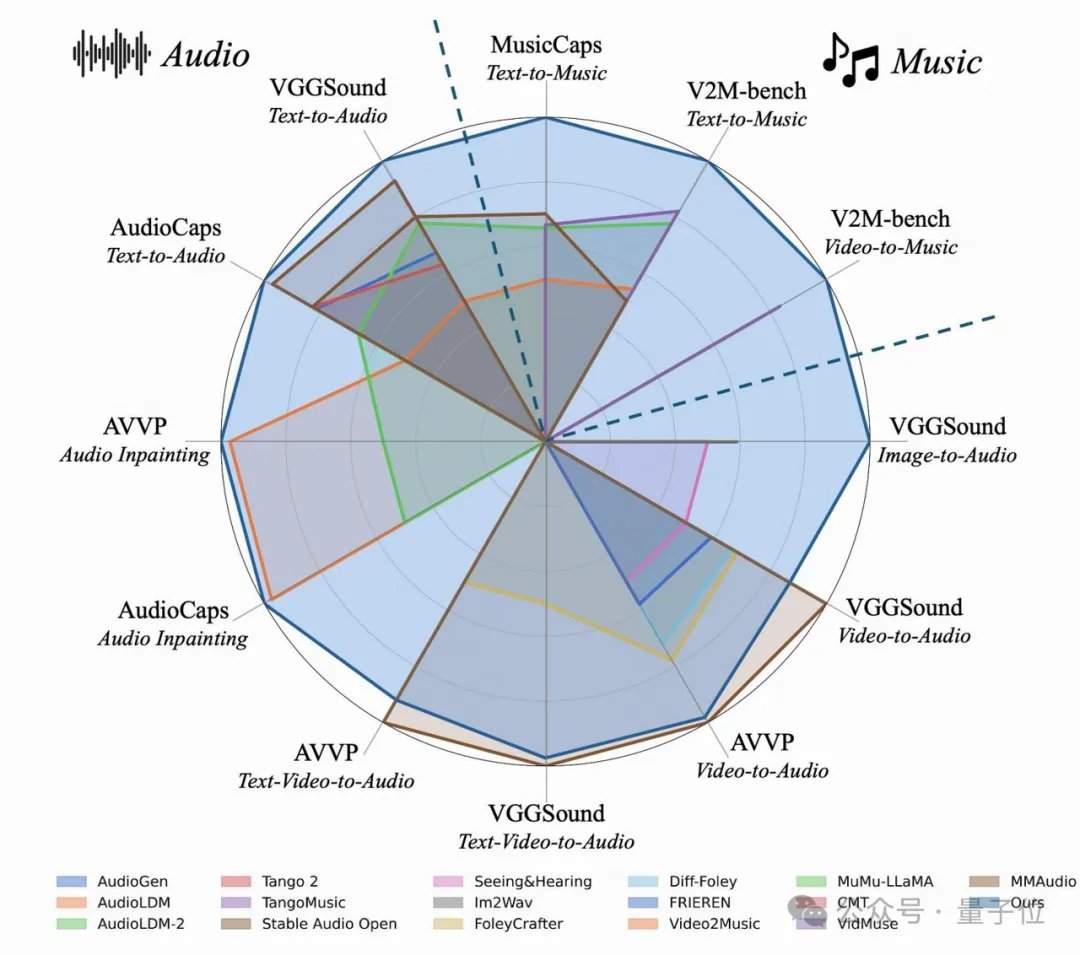
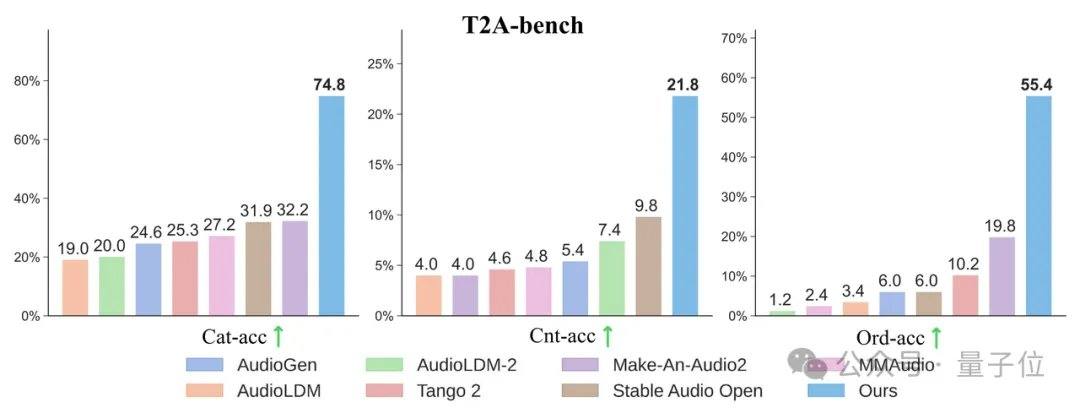
Исследовательская группа неожиданно обнаружила, что чем детальнее текстовые метки, тем лучше не только качество генерации аудио из текста, но и значительно улучшается синхронизация при озвучивании немых видео. В классических тестовых наборах, таких как AudioCaps и MusicCaps, модель AudioX-Turbo с 4 шагами превзошла или сравнялась по ключевым показателям качества звука с многочисленными базовыми моделями, требующими от 50 до 200 шагов. Для оценки способности следовать инструкциям команда создала специальный бенчмарк T2A-bench. В тестах на категорию звука, количество, временные метки и последовательность AudioX-Turbo показала подавляющее превосходство над другими базовыми методами, причем некоторые показатели улучшились более чем вдвое.
Три ключевых преимущества AudioX-Turbo: 4 шага вывода, снижение вычислительных затрат в 25 раз по сравнению с учительской моделью при лучшем качестве, RTF всего 0,02; набор данных с 9,2 миллиона строгих инструкций, впервые обеспечивающий точный контроль временных меток; поддержка мультимодального ввода (текст, видео, изображения) для генерации Anything-to-Audio. Весь обучающий код и веса модели проекта уже опубликованы в открытом доступе. Статья озаглавлена «AudioX-Turbo: A Unified Framework for Efficient Anything-to-Audio Generation», выполнена командами Noiz AI, Гонконгского университета науки и технологии и Университета Цинхуа. Домашняя страница проекта: https://zeyuet.github.io/AudioX-Turbo/.
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com