
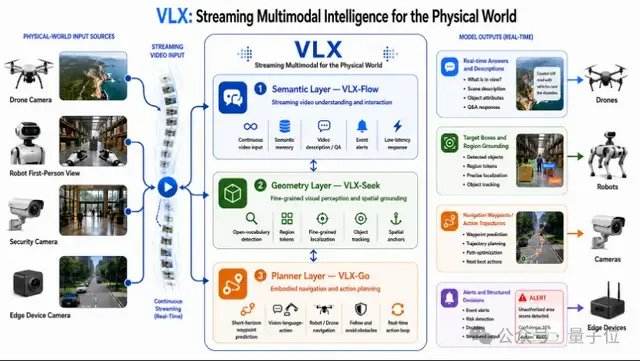
Репортаж от Wedoany,Ханчжоуская компания в сфере искусственного интеллекта Om AI выпустила первую в мире серию потоковых мультимодальных моделей VLX, ориентированных на физический мир и предназначенных для периферийных устройств. Серия включает три модели, которые будут выпущены в течение трех дней: VLX-Flow отвечает за потоковое восприятие в реальном времени, позволяя видео непрерывно поступать, как поток воды, а модель в реальном времени наблюдает, анализирует и обновляет состояние мира; VLX-Seek отвечает за точное позиционирование, переходя от общего обзора к детальному рассмотрению и быстрому обнаружению целей; VLX-Go отвечает за принятие решений и действия, преобразуя результаты восприятия и позиционирования в реальные движения, определяя направление движения и последовательность операций.
Соединенные вместе, эти три модели образуют замкнутый цикл возможностей мультимодальной модели: от непрерывного восприятия и точного позиционирования до принятия решений и действий. Их нативная архитектура для периферийных устройств позволяет моделям работать непосредственно на таких устройствах, как смартфоны, дроны и роботы.
Om AI не впервые выходит в область визуально-языковых моделей. В прошлом году компания выпустила VLM-R1 — первый в мире открытый проект, внедривший парадигму обучения с подкреплением DeepSeek R1 в визуально-языковые модели. За 12 часов проект набрал более 2000 звезд на GitHub, за 48 часов возглавил мировой рейтинг GitHub и на сегодняшний день имеет более 6000 звезд.
Серия VLX разработана вокруг двух ключевых концепций: периферийные устройства и потоковая мультимодальность. Потоковая мультимодальность означает способность ИИ непрерывно и в реальном времени воспринимать окружающую среду в физическом мире, формируя полную цепочку возможностей от восприятия до точного позиционирования и действий. Это отличается от потоковой мультимодальности в голосовых помощниках, где акцент делается на взаимодействие человека и ИИ в реальном времени. VLX фокусируется на непрерывном наблюдении, анализе и инициировании действий ИИ в физическом мире, совершая переход от просмотра изображений к выполнению задач. С быстрым развитием таких областей, как воплощенный интеллект, пространственный интеллект и генерация видео, визуально-языковые модели перестают быть просто модулем возможностей языковых моделей и постепенно становятся новым поколением инфраструктуры для пространственного понимания, понимания видео и даже планирования действий. Данные CVPR этого года показывают, что доля работ, посвященных визуально-языковым и мультимодальным моделям, выросла с 4,9% в прошлом году до 10,6%, что делает это одним из самых быстрорастущих направлений исследований, где восприятие в реальном времени и позиционирование являются двумя наиболее важными ключевыми словами.
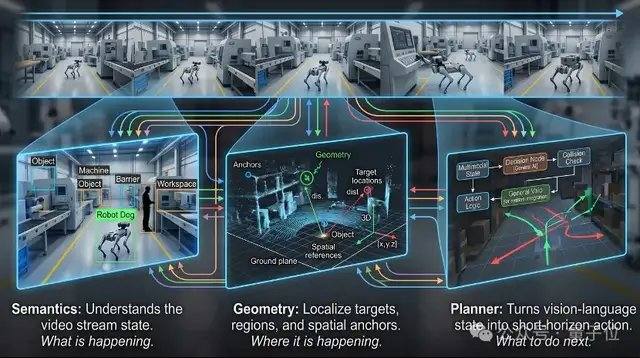
VLX-Flow отвечает за непрерывное восприятие. В реальном мире объекты постоянно движутся, среда непрерывно меняется, ракурсы часто переключаются, и однократное наблюдение не может справиться с динамичной, открытой и постоянно меняющейся средой. Традиционные видеомодели часто разбивают целое видео на кадры и отправляют их в модель для автономного понимания. При большой длительности видео это не только резко увеличивает вычислительные затраты, но и приводит к потере контекстной информации. Flow использует потоковую обработку: кадры непрерывно поступают, как поток воды, а визуальное состояние постоянно обновляется с помощью инкрементного кодирования и механизма кэширования, без необходимости повторного вычисления истории и без потери памяти при увеличении длины видео. На техническом уровне Flow использует Linear Attention вместо стандартного Attention в сочетании с двухуровневым механизмом памяти, что позволяет видеопотоку непрерывно поступать в модель без взрывного роста потребления видеопамяти из-за увеличения контекста.

VLX-Seek отвечает за детальное восприятие. Многие универсальные визуально-языковые модели, хотя и преуспевают в понимании семантики высокого уровня, имеют ограниченные возможности в таких задачах, как точное позиционирование, обнаружение объектов с открытым словарем и точная локализация (Grounding). Традиционные методы используют авторегрессивный подход, предсказывая положение цели координата за координатой, что медленно и подвержено ошибкам. Seek меняет подход: вместо угадывания координат он сначала генерирует области-кандидаты, а затем выполняет поиск и сопоставление, превращая процесс позиционирования в выбор области. В частности, Seek использует Region Token вместо традиционной генерации координат, что позволяет значительно уменьшить размер модели и затраты на развертывание на периферийных устройствах, сохраняя при этом способность к распознаванию. Этот подход больше соответствует самой задаче визуального восприятия, поэтому даже при меньшем размере модели он обеспечивает стабильную производительность в задачах обнаружения объектов с открытым словарем, точной локализации и отслеживания в реальном времени.

VLX-Go отвечает за действия. Традиционные визуально-языковые модели, даже если они знают, что цель находится слева впереди, в конечном итоге ограничиваются текстовым ответом. Для того чтобы действительно подойти к цели, обойти препятствия и непрерывно следовать за ней, требуется дополнительная система управления. Go принимает на вход монокулярное видео, историческую визуальную память и команды на естественном языке, обрабатывая их непосредственно в краткосрочные путевые точки, выполнимые роботом, и предсказывая, как следует двигаться в ближайшем будущем, а не просто выдает текстовые рекомендации. Go сочетает обучение траекториям в автономном режиме и обучение с подкреплением в онлайн-режиме, постоянно корректируя стратегию движения в замкнутом цикле симуляции, что позволяет роботу непрерывно адаптировать траекторию на основе визуальной обратной связи в реальном времени, обеспечивая стабильную производительность в задачах следования за целью, навигации и динамического уклонения от препятствий. Для удовлетворения требований управления в реальном времени на периферийных устройствах Go использует легковесную схему прогнозирования краткосрочных путевых точек, выполняя планирование движения в реальном времени всего с 0,6B параметров.
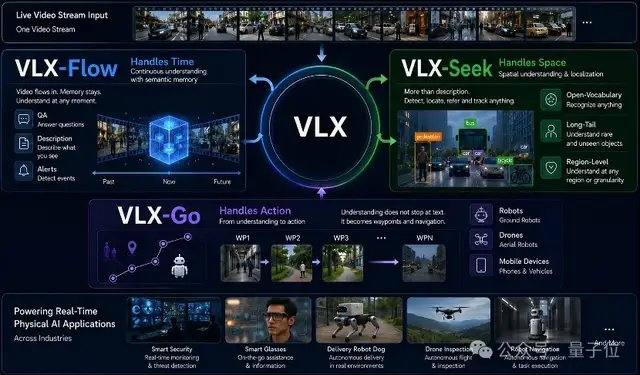
Модели Flow, Seek и Go не являются независимыми друг от друга, а используют общую базовую платформу и выполняют сквозное взаимодействие в одном и том же видеопотоке. От непрерывного восприятия до точного позиционирования и принятия решений о действиях — все три вместе образуют полную цепочку возможностей VLX, ориентированную на физический мир.
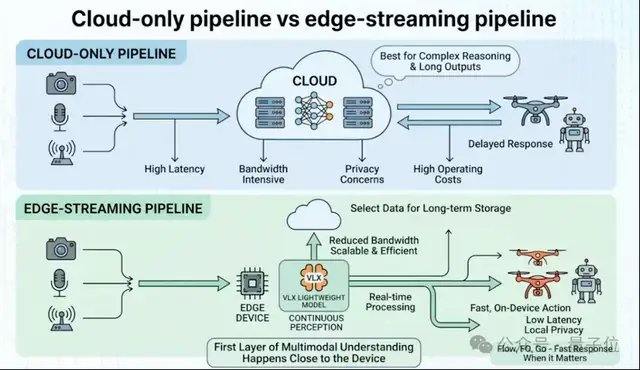
Для таких устройств физического мира, как роботы, дроны и камеры, развертывание на периферийных устройствах является предпосылкой для реального внедрения модели. Хотя многие облачные мультимодальные модели уже достаточно мощны, они не подходят для роботов и воплощенных сценариев, поскольку реальный мир непрерывен, динамичен и ограничен в ресурсах. Обычный подход в отрасли заключается в том, чтобы сначала обучить как можно большую модель, а затем сжать ее для работы на периферийных устройствах с помощью квантования, дистилляции и других методов. VLX выбрала другой путь: с самого начала проектирования вся система была переработана с учетом вычислительных ограничений периферийных устройств, а архитектура модели, методы вывода и цепочка развертывания были разработаны для видеопотоков в реальном времени и периферийных устройств.
Данные показывают, что VLX-Flow обрабатывает один видеопоток всего за 0,06 секунды, одновременно стабильно обрабатывая несколько видеопотоков; VLX-Go, используя примерно в десять раз меньше параметров, достигает лучших показателей навигации, чем более крупные модели; VLX-Seek, будучи моделью уровня 3B, достигает или превосходит результаты более крупных универсальных моделей в таких задачах, как обнаружение объектов.

Om AI — это компания в сфере искусственного интеллекта из Ханчжоу. Основатель и генеральный директор Чжао Тяньчэн имеет докторскую степень по компьютерным наукам в CMU и является лауреатом премии У Вэньцзюня за достижения в области искусственного интеллекта. В команду входят специалисты из CMU, Университета Цинхуа, Чжэцзянского университета, Microsoft, Alibaba Cloud и других организаций, имеющие более 50 публикаций на ведущих конференциях и более 50 патентов на изобретения. В 2022 году Om AI получила первый сертификат на мультимодальную модель от Министерства промышленности и информатизации КНР. Выпущенная в этот раз серия VLX является последним достижением компании в области непрерывного восприятия, точного позиционирования и реальных действий.

Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com










