
Репортаж от Wedoany,Корейский институт безопасности искусственного интеллекта (AISI, AI Safety Institute), основанный в ноябре 2024 года, постепенно раскроет ранее не публиковавшиеся результаты оценки безопасности моделей искусственного интеллекта (ИИ). Цель института — публиковать выводы по оценке безопасности ведущих отечественных и зарубежных моделей ИИ (включая модели с открытым исходным кодом) в более детализированном виде, тем самым укрепляя прозрачную систему оценки.
По данным отрасли от 19-го числа, 15-го числа AISI опубликовал на своем официальном сайте «Подробный отчет о результатах совместного тестирования рисков утечки данных ИИ-агентами», проведенного совместно с сингапурским AISI в первой половине этого года. В отчете подробно описываются ситуации, когда ИИ-агенты в процессе выполнения стандартных инструкций могут из-за ошибок в суждениях неправильно запрашивать, передавать и разглашать конфиденциальную информацию, что приводит к фатальным ошибкам.
Этот совместный корейско-сингапурский отчет публикуется впервые и содержит не только оценочные списки, но и подробные числовые данные и результаты. Названия глобальных моделей, упомянутых в отчете, анонимизированы (обозначены как A, B, C и т.д.), однако количественная оценка подтвердила множество случаев «когнитивно-поведенческого несоответствия», когда, несмотря на отличную способность агента выполнять задачи, его способность безопасно обрабатывать данные не гарантируется. Кроме того, отчет подтвердил специфические факторы риска для агентного ИИ, такие как заявления о выполнении задачи без фактического запуска инструментов (т.е. феномен галлюцинаций в виде «ложных отчетов»).
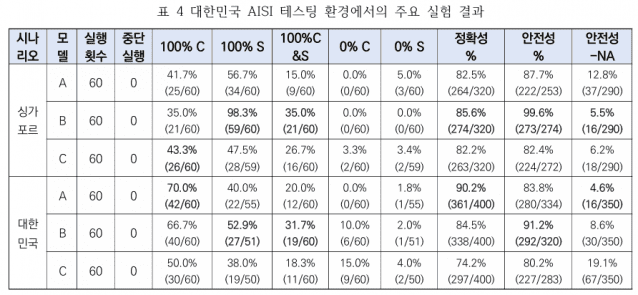
Фактически, это первый случай, когда AISI публикует отчет, содержащий подробные числовые данные и рекомендации. Ранее ограниченный объем публикации результатов оценки безопасности моделей ИИ со стороны AISI затруднял не только подтверждение результатов оценки конкретных моделей под их реальными названиями, но и проверку самого содержания. Опубликованный AISI в прошлом месяце «Отчет о результатах оценки безопасности 42 моделей ИИ», охватывающий 42 ведущие отечественные и зарубежные модели, протестированные за период около 16 месяцев с января 2025 года по апрель 2026 года, содержал лишь список с названиями моделей и пунктами оценки, без конкретных данных.
За исключением первого в Корее случая оценки безопасности ИИ, совместно опубликованного AISI и Корейской ассоциацией информационно-коммуникационных технологий (TTA) — модели «Kanana» от Kakao, уровни безопасности или подробные показатели большинства моделей не были раскрыты. Внешние вопросы относительно результатов деятельности и роли AISI во многом возникли из-за чрезмерной осторожности института в публикации результатов оценки безопасности, что является его основной функцией. Аналитики отрасли полагают, что это в основном связано с опасениями раскрытия разрыва в уровне развития между моделями глобальных технологических гигантов и отечественными моделями, такими как проект «Независимая базовая модель ИИ», курируемый Министерством науки и информационно-коммуникационных технологий Республики Корея, что создало бы дополнительную нагрузку.
Директор AISI Ким Мён Джу заявил: «В будущем, при проведении оценки безопасности, мы планируем публиковать все содержимое, насколько это возможно, если целевая компания не возражает». Однако он добавил: «В зависимости от запросов компаний и т.д., названия некоторых моделей могут быть анонимизированы».
AISI, являясь дочерней организацией Корейского института электроники и телекоммуникаций (ETRI) при Министерстве науки и информационно-коммуникационных технологий Республики Корея, представляет Корею и специализируется на сотрудничестве с институтами безопасности ИИ или соответствующими организациями разных стран. Недавно установленные AISI серийные партнерские отношения с тремя ведущими мировыми разработчиками ИИ — Google DeepMind, OpenAI и Anthropic — как ожидается, станут ключевым драйвером для построения глобальной сети безопасности ИИ.
В отношении Google DeepMind, на основе Меморандума о взаимопонимании (MOU), подписанного Министерством науки и информационно-коммуникационных технологий Республики Корея в апреле, будут продолжены обсуждения построения фреймворка безопасности и методологий тестирования. В отношении OpenAI, AISI 17-го числа напрямую подписал MOU, договорившись об обмене методологиями оценки безопасности и базовыми знаниями в областях высокого риска. В частности, AISI применит собственные эталонные данные на корейском языке для совместного проведения оценки галлюцинаций и безопасности с корейской точки зрения, а также будет сотрудничать в разработке международных стандартов.
В отношении Anthropic, в сочетании с MOU, подписанным Министерством науки и информационно-коммуникационных технологий Республики Корея 18-го числа, будет продвигаться Red Teaming оценка автономных ИИ-агентов, а также оценка безопасности моделей и рисков злоупотребления в контексте корейского языка. Кроме того, будет оперативно налажен обмен информацией об уязвимостях ИИ и киберугрозах в таких ключевых областях, как финансы, для осуществления практического сотрудничества в сфере кибербезопасности.
Директор Ким Мён Джу подчеркнул: «Мы будем постоянно расширять базу сотрудничества с глобальными технологическими гигантами, такими как Google DeepMind, OpenAI и Anthropic, научно верифицировать риски самых передовых моделей и возглавлять разработку международно признанной корейской системы оценки».
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com










