Репортаж от Wedoany,Врачи из больниц третьего уровня, опрошенные Interface News, сообщили, что всё больше пациентов приходят на приём с результатами, сгенерированными ИИ, что увеличивает затраты на коммуникацию между врачом и пациентом. Один врач отметил, что из 30 пациентов, принятых за одно утро, 25 пришли с выводами ИИ. В этом контексте Baichuan Intelligence выпустила усиленную медицинскую большую модель Baichuan-M4, которая основана на структурной реконструкции общей большой модели и специализированном усилении в медицинской сфере, направленном на повышение надёжности ИИ в принятии медицинских решений.
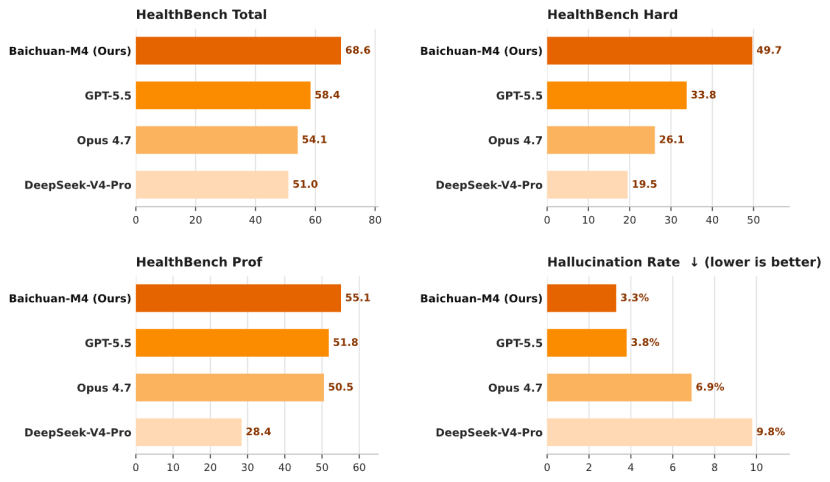
В последнем тесте HealthBench модель M4 набрала 68,6 балла в общем зачёте, 49,7 балла в сложных задачах, а уровень галлюцинаций снизился до 3,3%. В тесте HealthBench Professional, более приближенном к реальной клинической среде, базовая оценка рассуждений M4 составила 55,1 балла, что выше 51,8 балла у GPT-5.5.
Улучшение возможностей M4 проявляется на четырёх уровнях. Первый — динамическая диагностика: на основе системы SCAN-bench 2.0 сценарии обучения модели расширены с однократной стандартизированной консультации до многократных визитов и сложных профилей пациентов. В тесте SCAN-bench M4 набрала 79,0 баллов при первичном приёме и 74,7 балла при повторном; оценка долгосрочной клинической памяти составила 86,9 балла, что на 21,1 балла выше, чем у предыдущего поколения M3. Второй уровень — доказательная медицина: M4 построила атомарную систему клинических путей, разбив медицинские руководства на более чем 1000 повторно используемых клинических блоков принятия решений, охватывающих полные процессы диагностики и лечения более 200 распространённых заболеваний. В тесте Baichuan-EBM точность цитирования доказательств достигла 90,0, что значительно выше 54,7 у GPT-5.5.
Третий уровень — координация: M4 внедрила архитектуру Harness, позволяющую модели самостоятельно решать, когда задавать уточняющие вопросы, искать доказательства или извлекать историю болезни, одновременно выполняя операции в условиях ограничений реального времени. Четвёртый уровень — память о полном течении болезни: модель может объединять исторические медицинские записи, многократные консультации, тенденции анализов и отзывы о лекарствах, отслеживая в ходе нескольких диалогов историю болезни пациента и изменения показателей.
Потребительский продукт Baixiaoyi на основе модели M4 уже проходит внутреннее тестирование среди некоторых пользователей. Этот продукт может постепенно дополнять информацию об истории болезни в ходе многократных диалогов, сужать диапазон оценки рисков и при необходимости направлять пользователя к врачу. Согласно данным, опубликованным Baichuan Intelligence, в ходе тестирования в таких учреждениях, как Онкологическая больница Китайской академии медицинских наук (отделение онкологии), Пекинская детская больница при Столичном медицинском университете (отделение педиатрии) и больница Жуйцзинь при Шанхайском университете Цзяотун (отделение респираторной и критической медицины), за 27 дней в 75 группах пациентов было сгенерировано 6944 диалога. Безопасность Baixiaoyi достигла 99,6%, а глубина взаимодействия — от 60% до 73%.

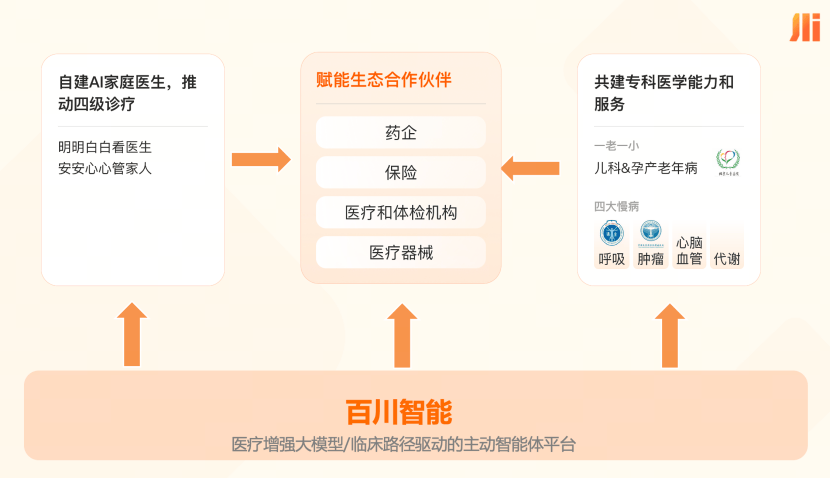
Baichuan Intelligence позиционирует M4 как «мозг» для медицинских сценариев, а Baixiaoyi — как «тело», соединяющее пользователя. Первый отвечает за профессиональные рассуждения, доказательную медицину и долгосрочную память, а второй переносит эти возможности в домашние условия. Компания планирует реализовать «двухврачебную модель», при которой ИИ отвечает за долгосрочное сопровождение вне кабинета, систематизацию информации и напоминания о рисках, а реальные врачи — за диагностику и принятие решений о лечении.
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com