Репортаж от Wedoany,GitHub в сотрудничестве с командой Microsoft Security & AI’s Agents Offense team применил метод верификации Agentic Secret Finder, внедрив более глубокий контекстный анализ в процесс проверки секретов GitHub. Этот метод объединяет масштабный конвейер обнаружения GitHub с контекстной верификацией на основе LLM, что позволило снизить уровень ложных срабатываний на 75,76%, превысив изначально установленную цель в 65%. В ходе оценки команда протестировала метод на 1500 подтверждённых клиентами ложных срабатываниях. Учитывая огромный масштаб кодовой базы GitHub, проблема ложных срабатываний при сканировании секретов долгое время беспокоила разработчиков, а избыток низкокачественных оповещений подрывал доверие к системе.

Традиционное обнаружение на основе сопоставления шаблонов, хотя и способно идентифицировать строки, похожие на секреты, с трудом отличает реальные утечки от значений, которые лишь выглядят конфиденциальными. Чтобы решить эту задачу, команда не стала просто увеличивать объём анализируемых данных, а сосредоточилась на извлечении небольшого набора высокоинформативных сигналов. Например, система проверяет, передаётся ли значение, присвоенное переменной, в API-запросы, заголовки аутентификации, клиенты баз данных или вызовы облачных SDK. Исследование показало, что большинство ложных срабатываний можно устранить, используя только контекст на уровне файла, тогда как передача всего файла или репозитория вносит слишком много шума, увеличивая затраты и задержки. Эта стратегия «лучшего контекста», а не «большего контекста», позволяет системе более эффективно отличать реальные секреты от тестовых данных или заполнителей.

Данный метод напрямую построен на существующей системе сканирования секретов GitHub, усиливая контекстную осведомлённость этапа верификации без изменения логики вышестоящего обнаружения или снижения охвата. Изначально сканирование секретов GitHub сочеталось с обнаружением на основе шаблонов и AI-управляемым обнаружением общих секретов, охватывая миллиарды отправок от десятков миллионов разработчиков в миллионах репозиториев. Целью данного сотрудничества было повышение точности обнаружения секретов с помощью AI до того же высокого стандарта, что и при обнаружении на основе шаблонов провайдеров.
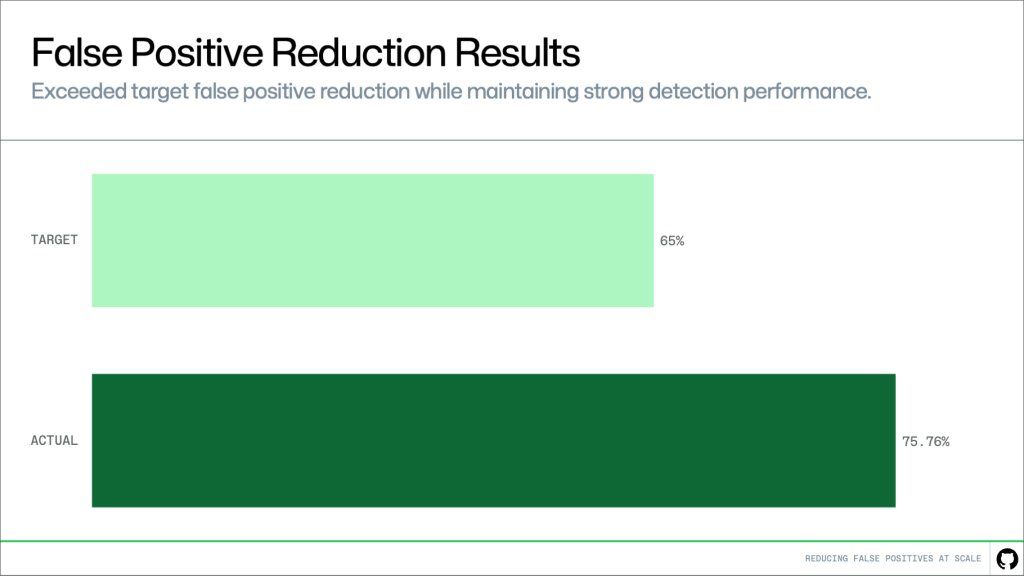
Это улучшение напрямую отразилось на опыте разработчиков. Сокращение количества нерелевантных оповещений позволяет разработчикам быстрее расставлять приоритеты и устранять действительно важные проблемы. В настоящее время GitHub продолжает оценивать этот метод на более крупных наборах данных и в реальном трафике, а также дополнительно оптимизирует процессы извлечения контекста и верификации.
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com