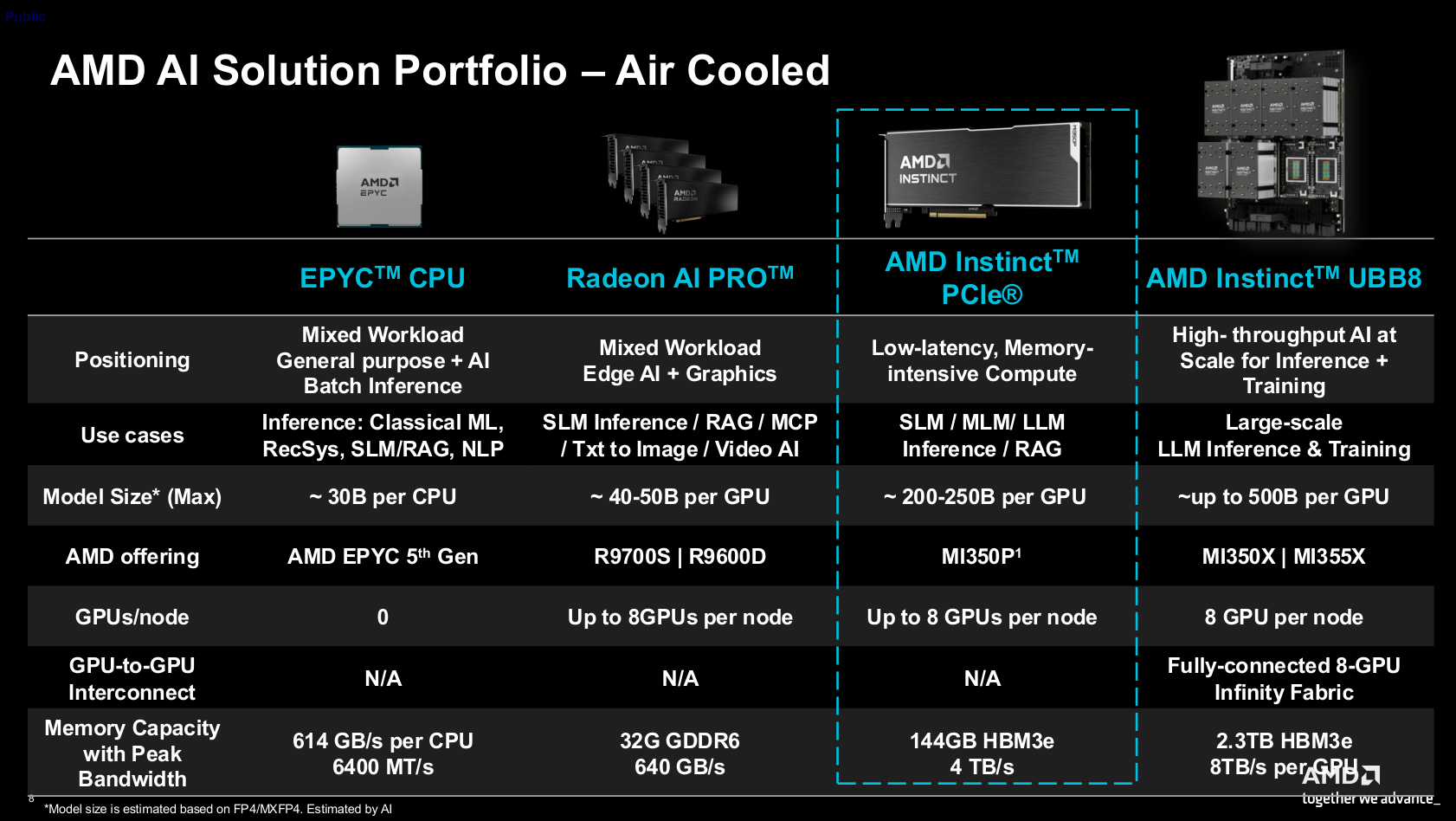
Репортаж от Wedoany,Американская компания AMD выпустила Instinct MI350P для серверных сред. Эта карта совместима со стандартными слотами PCIe 5.0 и нацелена в первую очередь на агентный искусственный интеллект, то есть на ИИ-агентов, способных активно помогать пользователям в выполнении задач. Изделие выполнено в двухслотовом форм-факторе длиной около 26,7 см и использует пассивное охлаждение, полагаясь на мощный воздушный поток внутри стоечного сервера. Его стековая память HBM3e объемом 144 ГБ гарантирует возможность обработки ИИ-моделей с 200–250 миллиардами параметров, тогда как рабочая видеокарта Radeon AI Pro 9700, оснащенная всего 32 ГБ видеопамяти, упрется в узкое место уже в районе 40–50 миллиардов параметров.
Архитектура GPU у MI350P та же, что и у Instinct MI350X/355X в форм-факторе открытого ускорительного модуля, но конфигурация урезана вдвое. У этой карты активировано лишь 128 вычислительных блоков, тогда как OAM-версия располагает 256 CU; объем высокоскоростной памяти HBM3e также уменьшен с 288 ГБ до 144 ГБ. Официально производитель письменно это не подтверждает, но изображения продукта показывают, что на нем установлен только один чип ввода-вывода и четыре вычислительных чипа, что эквивалентно разделению пополам упаковки GPU полноразмерной версии.
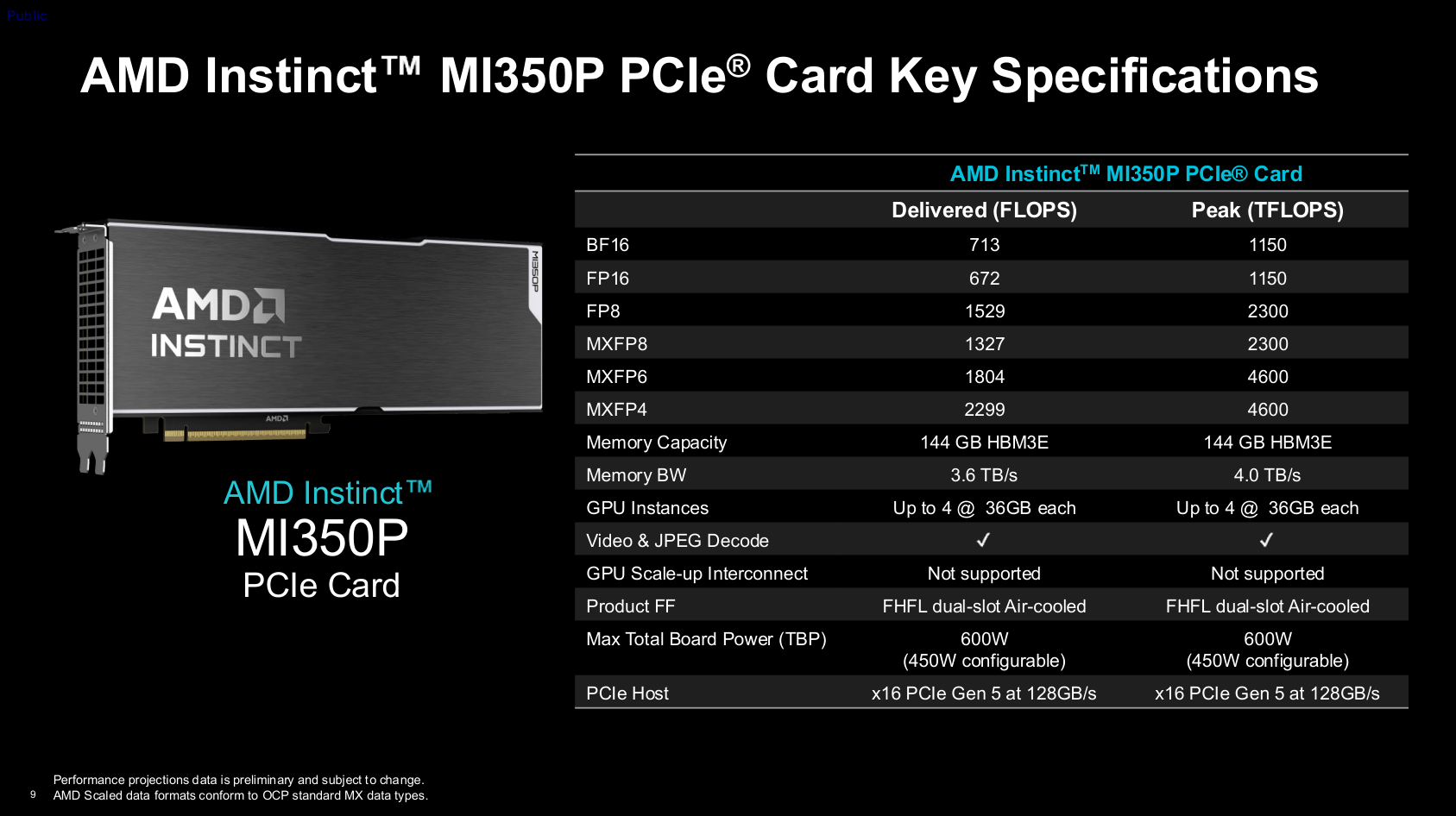
Что касается энергопотребления, номинальная расчетная тепловая мощность составляет 600 Вт, что находится в сопоставимом диапазоне с Nvidia RTX Pro 6000 Blackwell или H200 NVL; используется разъем питания 12V-2×6, также возможен переход в режим 450 Вт. Для поддержки параллельной работы нескольких пользователей на карте предусмотрены три способа разделения: SPX, DPX и CPX. SPX — это полноскоростной режим; DPX поровну делит вычислительные блоки, память, а также ресурсы видео- и JPEG-движков между двумя пользователями; CPX делит карту на четыре части, при этом два раздела совместно используют один видеодвижок и одну группу из десяти ядер JPEG-движка. Весь чип способен одновременно обрабатывать 99 видеопотоков 1080p30 AV1 или кодировать/декодировать 4425 изображений JPEG формата 1080p в секунду.
Что касается теоретической пиковой производительности, на операциях FP8 она может достигать 2300 Терафлопс (для плотных матриц), а с использованием разреженности этот показатель примерно удваивается; для MXFP4 и MXFP6 она составляет 4600 Тфлопс. Этот уровень немного ниже половины производительности MI355X, в то время как аналогичный показатель для плотных матриц у Nvidia H200 NVL составляет около 1670 Тфлопс. При оценке реальной пропускной способности MI350P обычно достигает 60–70% от максимальной скорости, и только для MXFP6 реализуется лишь 40% от теоретического значения, что не дает двукратного прироста по сравнению с FP8.
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com