
Репортаж от Wedoany,22 июня компания Baidu выпустила в открытый доступ модель Unlimited OCR, предназначенную для решения проблемы замедления работы сквозных OCR-моделей при обработке длинных документов. Общее количество параметров модели составляет 3 миллиарда, при этом во время вывода активируется только 500 миллионов параметров.
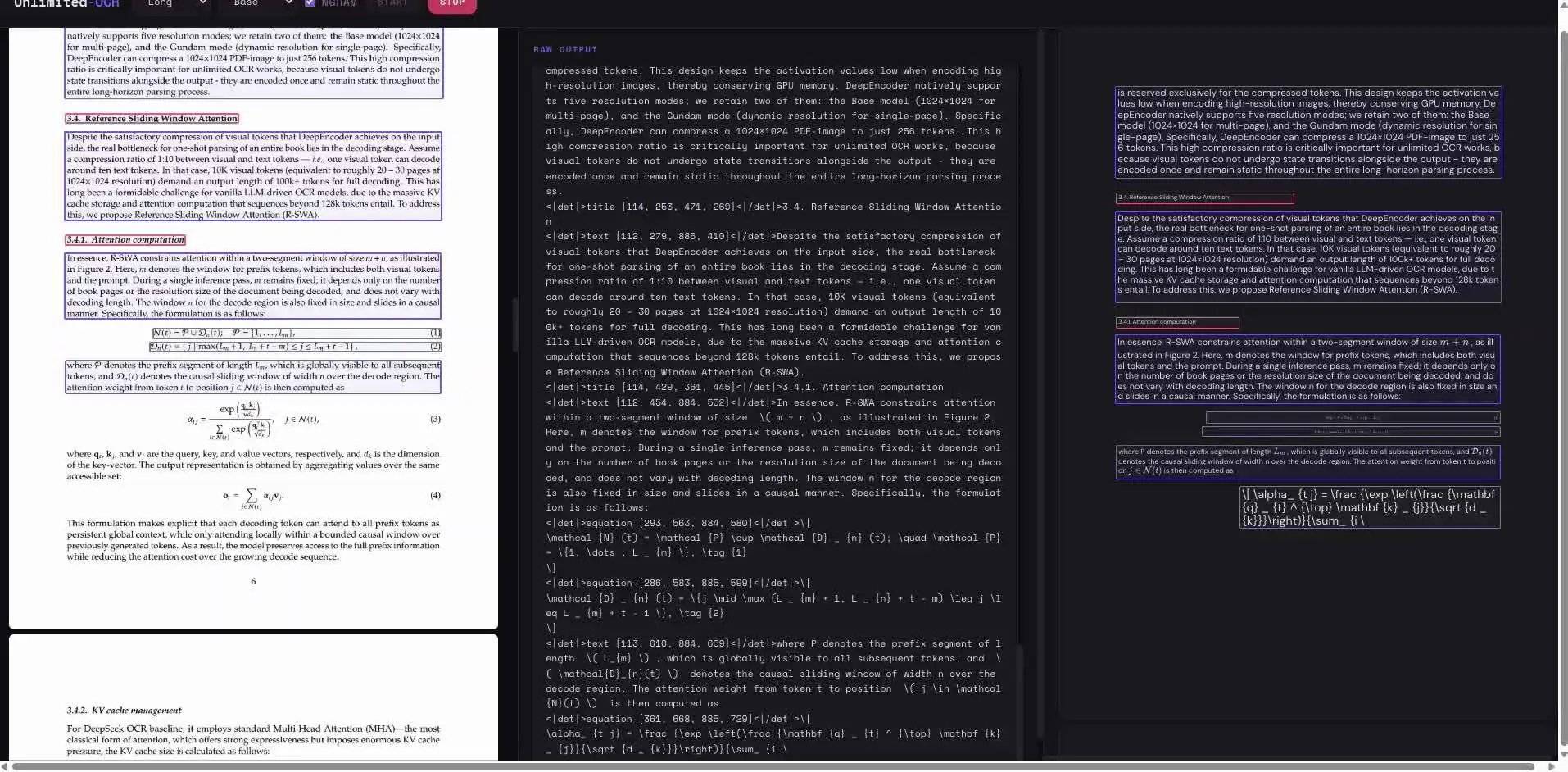
Сквозные OCR-модели используют единую архитектуру нейронной сети, объединяя обнаружение текста и распознавание символов в одной системе, напрямую преобразуя входное изображение в текстовую последовательность, отказываясь от традиционного процесса сначала обнаружения текстовых блоков, а затем их отдельного распознавания. Каждый сгенерированный токен в основных сквозных OCR-моделях увеличивает кэш ключей и значений (KV cache), что приводит к постоянному росту использования видеопамяти и задержки, и пользователи замечают, что обработка многостраничных документов замедляется к концу.
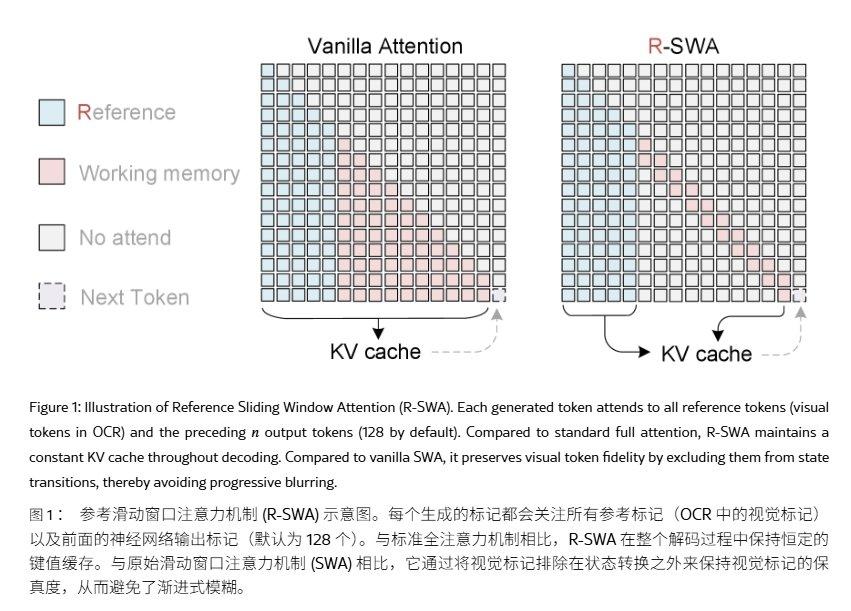
Unlimited OCR продолжает архитектуру DeepSeek OCR, сохраняя DeepEncoder и декодер смеси экспертов (MoE). На стороне кодирования используется двухуровневое визуальное кодирование, на этапе соединения выполняется 16-кратное сжатие токенов, сжимая PDF-изображение размером 1024×1024 в 256 визуальных токенов, что снижает нагрузку на предварительное заполнение на начальном этапе.
Что касается обучения, Unlimited OCR продолжает обучение на контрольной точке DeepSeek OCR в течение 4000 шагов, замораживая DeepEncoder и обучая только декодер. Данные для обучения включают около 2 миллионов образцов документов, обучение проводится на 8×16 A800 GPU. Соотношение данных: примерно 9:1 для одно- и многостраничных документов, многостраничные образцы создаются путем конкатенации.
Бенчмарки показывают, что Unlimited OCR набирает 93,23 балла в OmniDocBench v1.5, что выше 87,01 у DeepSeek OCR и 89,17 у DeepSeek OCR 2. Его расстояние редактирования текста составляет 0,038, CDM для формул — 92,61, TEDS для таблиц — 90,93, а расстояние редактирования порядка чтения — 0,045. В OmniDocBench v1.6 общий балл модели достигает 93,92.

Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com










