Репортаж от Wedoany,Народный университет Китая совместно с Microsoft Research представили фреймворк Arbor, который преобразует процесс автономной оптимизации ИИ-систем из метода проб и ошибок в механизм накопительного обучения. Благодаря структурированному управлению гипотезами, фреймворк обеспечивает проверяемое повышение производительности более чем в 2,5 раза в реальных инженерных задачах.

С ростом возможностей больших языковых моделей и ИИ-систем автономная оптимизация становится ключевой задачей. Инженерные команды при оптимизации ИИ-агентов часто вынуждены одновременно настраивать множество параметров, таких как стратегия разбиения, методы поиска, системные подсказки и т.д. Эти корректировки взаимосвязаны, что затрудняет точное определение причин и приводит к низкой эффективности процесса оптимизации. Соавтор статьи Цзяцзе Цзинь отмечает, что простое предоставление кодирующему агенту большего времени или вычислительных ресурсов не приводит к лучшим результатам: «Если цель нечеткая или метрики легко поддаются манипуляции, длительная работа обычно лишь быстрее порождает „улучшения“, которые на самом деле никому не нужны».
Существующие кодирующие агенты полагаются на записи диалогов в качестве памяти, но задачи автономной оптимизации включают сотни раундов взаимодействия, что легко превышает ограничения контекстного окна. Агентам сложно сохранять фактические доказательства в длинной истории, теряется общая структура исследовательского процесса, они склонны застревать на ранних неудачах или гоняться за шумными колебаниями оценок. Кроме того, универсальные фреймворки организуют цепочки вызовов инструментов в общем рабочем дереве, что не позволяет тестировать параллельные гипотезы в изолированной среде.
Arbor решает эту проблему с помощью архитектуры разделения верхнего и нижнего уровней: координатор выступает в роли главного исследователя, управляя глобальным состоянием оптимизационного исследования, выдвигая гипотезы и определяя направление экспериментов, не редактируя напрямую код; исполнитель — это короткоживущий агент, тестирующий конкретные гипотезы в независимом git-рабочем дереве. Два компонента взаимодействуют через механизм «уточнения дерева гипотез», представляя исследовательский процесс в виде постоянного дерева ветвей, где каждый узел связан с гипотезой, исполняемым артефактом, фактическими доказательствами и извлеченными инсайтами. Координатор размещает широкие идеи в корневом узле, а конкретные уточнения — в листовых узлах, что позволяет одновременно исследовать несколько конкурирующих направлений. Неудачные эксперименты фиксируются как отрицательные ограничения, предотвращая повторение системой одних и тех же ошибок.
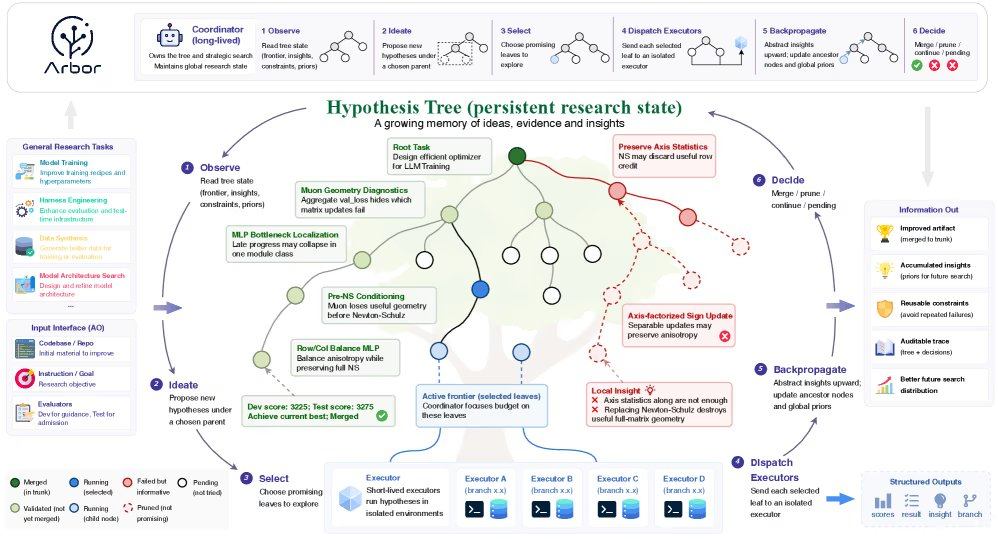
В реальных инженерных сценариях Arbor обеспечивает четкую атрибуцию свойств, представляя каждый оптимизационный рычаг в виде отдельной гипотезы. После того как исполнитель возвращает отчет, координатор записывает доказательства в дерево и распространяет инсайты обратно к родительскому узлу. Для предотвращения переобучения фреймворк применяет «шлюз слияния», тестируя кандидатов в независимых рабочих деревьях и объединяя их с текущей лучшей основной ветвью только при повышении удерживаемых тестовых оценок.
Исследователи оценили Arbor на наборе задач автономной оптимизации, основанном на реальных исследовательских средах, и на бенчмарке машинного обучения MLE-Bench Lite. Набор AO включает задачи по обучению моделей, разработке фреймворков и синтезу данных. При использовании базовых моделей, таких как Claude Opus 4.6, GPT-5.5 и Gemini-3-Flash, средний относительный прирост Arbor более чем в 2,5 раза превышает показатели Codex и Claude Code. В задаче BrowseComp по оптимизации поискового агента Arbor повысил удерживаемую точность системы с 45,33% до 67,67%, в то время как Codex и Claude Code остановились на 50% и 53,33% соответственно. На MLE-Bench Lite Arbor показал наилучшие результаты при использовании GPT-5.5.
Arbor демонстрирует устойчивость к переобучению. В экспериментах Terminal-Bench 2.0 Claude Code получил 75 баллов на разработке, но снизился до 71 на удерживаемых данных; Arbor показал более низкий балл на разработке — 72,22, но достиг наивысшего удерживаемого балла — 77,36. Эксперименты по переносу между задачами показали, что кодовая база, оптимизированная для задачи BrowseComp, может значительно повысить производительность на несвязанных задачах HLE и DeepSearchQA.
Фреймворк спроектирован для работы поверх существующего Git-воркфлоу. Цзинь отмечает, что Arbor выводит обычные git-ветки, которые могут быть напрямую проверены существующими процессами ревью кода и ручной проверки. Основные затраты при развертывании связаны с потреблением токенов для поддержания координатора и управления деревом, а также с вычислительными и дисковыми ресурсами для нескольких изолированных рабочих деревьев. Фреймворк подходит для задач с четкими надежными метриками, допускающих длительные временные промежутки и имеющих несколько разумных направлений поиска, таких как оптимизация пайплайнов, качество синтеза данных и настройка обучения моделей. Он не должен применяться для задач реального времени, простых исправлений или сценариев с дефектными метриками оценки. Цзинь считает, что следующим шагом эволюции станет переход от единичных скалярных оценок для каждого узлового артефакта к многокритериальному поиску Парето, учитывающему векторы точности, задержки и стоимости.
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com