Репортаж от Wedoany,1 июня китайская компания в сфере искусственного интеллекта MiniMax представила новую универсальную модель MiniMax M3. Модель основана на собственной архитектуре MiniMax Sparse Attention, API поддерживает контекстное окно до 1 млн токенов с гарантированной доступностью не менее 512 тыс. токенов, и ориентирована в первую очередь на долгосрочных агентов, сложные задачи кодирования и нативные мультимодальные приложения.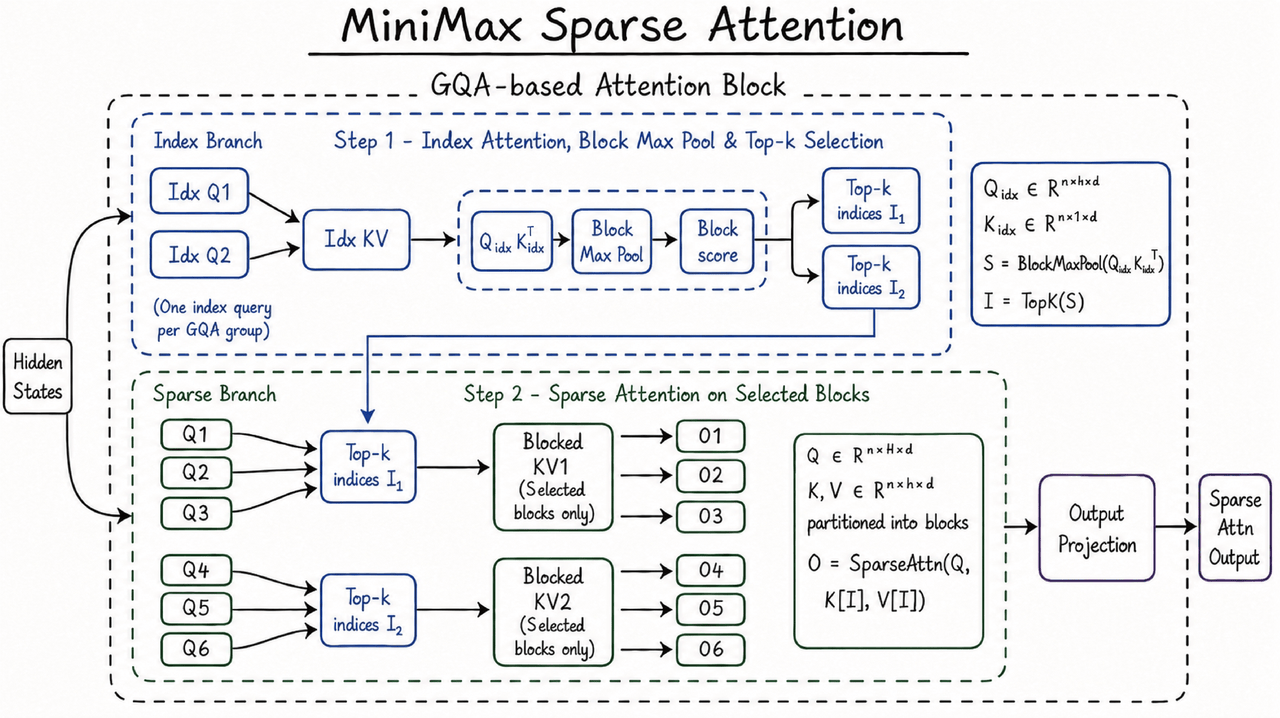
Ключевое изменение в MiniMax M3 заключается в переходе возможностей длинного контекста от «параметрических показателей» к «решению инженерных задач». На этапе внедрения больших языковых моделей (LLM) в агентные приложения модели больше не требуется обрабатывать только однораундовые диалоги или генерацию коротких текстов. Вместо этого она имеет дело с длинными задачами, где переплетаются репозитории кода, техническая документация, журналы задач, записи вызовов инструментов, изображения и видео. Контекстное окно в 1 млн токенов означает, что MiniMax M3 может сохранять больше информации из выше- и нижестоящих этапов в рамках одной цепочки задач, уменьшая потери информации, вызванные частыми обрывами, повторными суммаризациями и внешним поиском. Для таких сценариев, как разработка ПО, воспроизведение научных исследований, вопросно-ответные системы по корпоративным базам знаний, понимание длинных видео и сложная автоматизация офисной работы, длинный контекст становится ключевой базовой способностью для стабильного внедрения модели в производственные процессы.
Эту возможность обеспечивает собственная архитектура MiniMax Sparse Attention (MSA). Традиционные механизмы полного внимания сталкиваются с проблемой быстрого роста вычислительных затрат при увеличении длины контекста. MSA улучшает вычислительную эффективность при длинном контексте за счет разреженного внимания, позволяя MiniMax M3 поддерживать приемлемую производительность вывода в контекстном окне из миллионов токенов. Согласно официальной информации, при длине контекста в 1 млн токенов вычислительные затраты на один токен в M3 составляют примерно 1/20 от затрат модели предыдущего поколения, скорость на этапе предварительного заполнения увеличена более чем в 9 раз, а на этапе декодирования — более чем в 15 раз. Для разработчиков и корпоративных пользователей такие изменения эффективности напрямую влияют на стоимость API, скорость отклика и способность к непрерывному выполнению длительных задач, а также определяют, сможет ли MiniMax M3 перейти от демонстрационных сценариев к более частым бизнес-вызовам.
MiniMax M3 также делает акцент на возможностях кодирования и агентных способностях. Задачи в области программной инженерии стали ключевым полем конкуренции для LLM, поскольку реальный процесс разработки обычно включает уточнение требований, модификацию кода, обратную связь по тестированию, вызов инструментов, итерацию версий и многораундовое сотрудничество. MiniMax сообщает, что M3 достиг высоких результатов в таких бенчмарках, как SWE-Bench Pro, Terminal-Bench 2.1, KernelBench Hard, MCP Atlas, и обучался адаптироваться к сценариям непрерывного сотрудничества с помощью фреймворка симуляции пользователей. Это направление показывает, что MiniMax M3 стремится улучшить способности не просто «написать фрагмент кода», а охватить полную цепочку разработки: от декомпозиции задачи, выполнения, верификации до многократного исправления.
Мультимодальность также является одной из ключевых возможностей MiniMax M3. Модель с ранних этапов обучения использует смешанные модальные данные, что позволяет тексту, изображениям и видео обрабатываться совместно в рамках единой задачи. В официальных примерах MiniMax M3 используется для таких длительных задач, как воспроизведение научных статей, оптимизация операторов CUDA и автоматизация процесса обучения моделей, демонстрируя комбинированную ценность длинного контекста, способностей к кодированию, вызова инструментов и мультимодального понимания. Для корпоративных AI-приложений такие комбинированные возможности означают, что модель может одновременно читать документы, понимать диаграммы, анализировать журналы, генерировать код и вызывать инструменты, расширяя границы агентных приложений от «точечных способностей» до «межшагового выполнения».
Запуск MiniMax M3 также отражает переход конкуренции в сфере китайских LLM от простых параметров модели, цен и общего диалогового опыта к таким более приближенным к производственной среде способностям, как длинный контекст, выполнение агентных задач, инженерия кода и мультимодальная интеграция. По мере того как предприятия интегрируют LLM в процессы разработки, операционной деятельности, обслуживания клиентов, офисной работы и управления знаниями, производителям моделей необходимо одновременно решать проблемы производительности, стоимости, емкости контекста, стабильности и экосистемы инструментов. Инвестиции MiniMax M3 в миллионный контекст и архитектуру MSA показывают, что долгосрочные агенты становятся новым фокусом конкуренции в коммерциализации больших языковых моделей.
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com