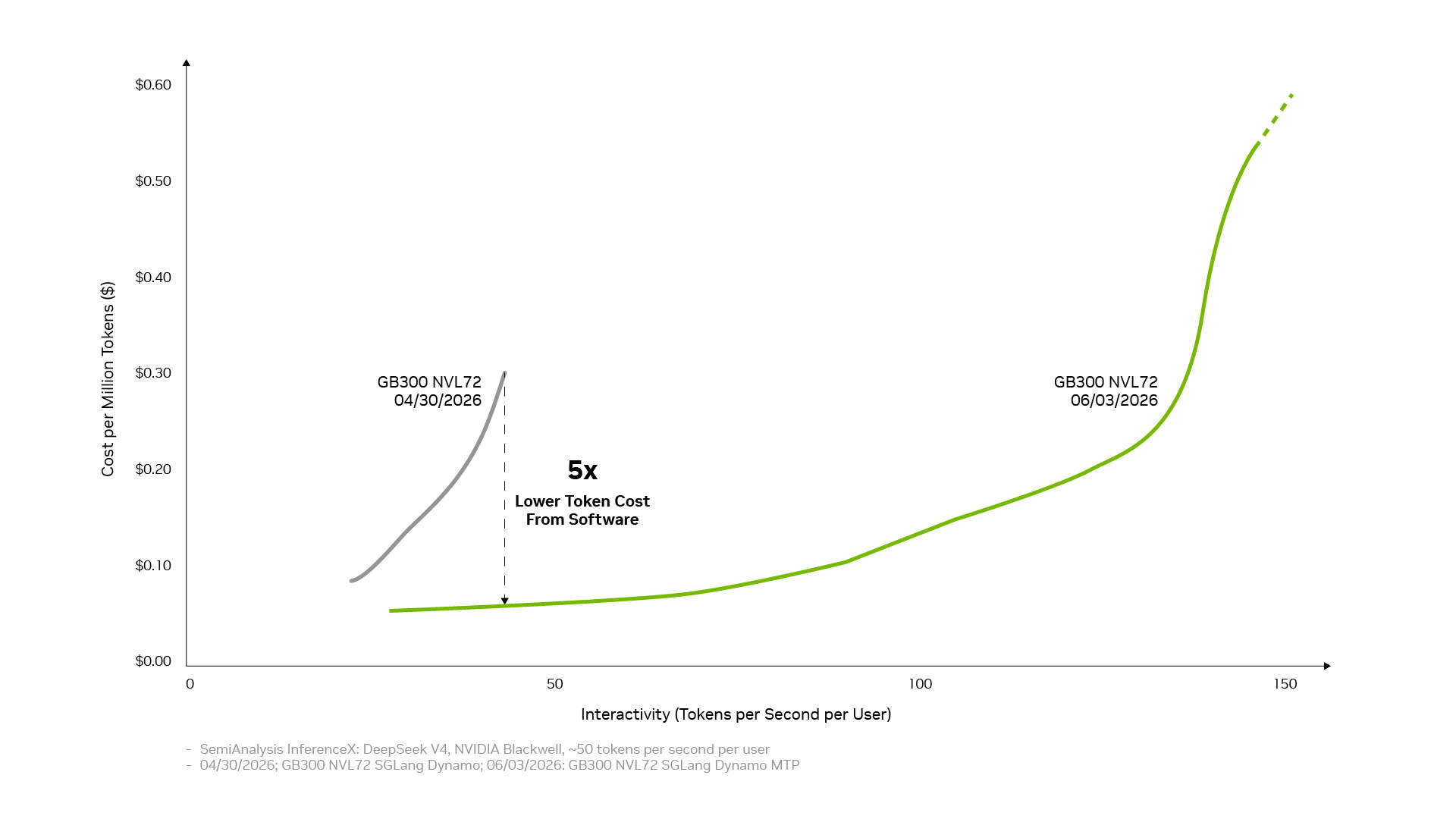
Репортаж от Wedoany,Программный стек вывода NVIDIA на платформе Blackwell позволил за один месяц снизить стоимость одного токена модели DeepSeek V4 максимум до одной пятой от первоначальной. По мере того как компании переходят от пилотных проектов ИИ к производственным ИИ-фабрикам, решения об инфраструктуре сместились с фокуса на пиковые характеристики чипов к стоимости одного токена, то есть к тому, сколько полезных токенов производится на каждый доллар и каждый ватт электроэнергии при соблюдении целевых показателей задержки. Программный стек вывода NVIDIA, спроектированный совместно с GPU, CPU, сетевыми и системными решениями NVIDIA и усиленный обширной экосистемой с открытым исходным кодом, постоянно повышает производительность оборудования.
Ведущие компании и поставщики услуг вывода уже начали ощущать совокупную ценность программного стека вывода NVIDIA на Blackwell. Baseten использует библиотеку с открытым исходным кодом NVIDIA TensorRT-LLM для предоставления услуг DeepSeek V4 Pro на GPU Blackwell, подходящих для задач вывода, кодирования и длинных контекстов, достигая увеличения количества выводимых токенов в секунду до 50% за счет оптимизации собственной среды выполнения. Cognition использует фреймворк вывода NVIDIA Dynamo для управления GPU вывода, предоставляя своей команде готовый путь для масштабирования рабочих нагрузок с обучением с подкреплением без необходимости создавать инфраструктуру с нуля. Deep Infra использует программный стек вывода NVIDIA для высокопроизводительного запуска передовых моделей с открытым исходным кодом, включая DeepSeek V4, на Blackwell с первого дня. Together AI использует NVIDIA TensorRT-LLM на Blackwell, помогая Cursor ускорить путь от оптимизации модели до производственной конечной точки для поддержки их опыта кодирования в реальном времени.
Традиционные рабочие нагрузки веб-сервисов, поиска и программного обеспечения как услуги относительно предсказуемы, в отличие от агентного ИИ. Агенты могут рассуждать, планировать, вызывать инструменты, запускать специализированные под-агенты и управлять большими объемами контекста в многошаговых рабочих процессах, превращая отдельный запрос в распределенную вычислительную задачу, которая может включать сотни под-агентов, тысячи задач и несколько больших языковых моделей, работающих на GPU, CPU, DPU и системах хранения. Программный стек определяет, превратится ли эта сложность в растраченные вычислительные мощности или в более низкую стоимость одного токена.
Более низкая стоимость одного токена достигается путем преобразования отдельных оптимизаций в системную производительность. Программный стек вывода NVIDIA делает это, соединяя три уровня: уровень производственной эксплуатации координирует распределенные сервисы, оркестрацию, автоматическое масштабирование и управление памятью; уровень ускорения приложений обеспечивает высокопроизводительный запуск моделей и предоставляет разработчикам пространство для настройки и кастомизации; уровень доступа к инфраструктуре раскрывает возможности GPU, сетей, памяти и систем NVIDIA. Когда эти уровни работают вместе как единая система, эффекты от отдельных оптимизаций суммируются. Разделение сервисов, крупномасштабный параллелизм экспертов на основе технологии взаимосвязи NVIDIA NVLink, точность NVFP4 и многотокенное прогнозирование — каждое из этих решений дает значительный выигрыш, а их комбинация может увеличить пропускную способность до 20 раз.
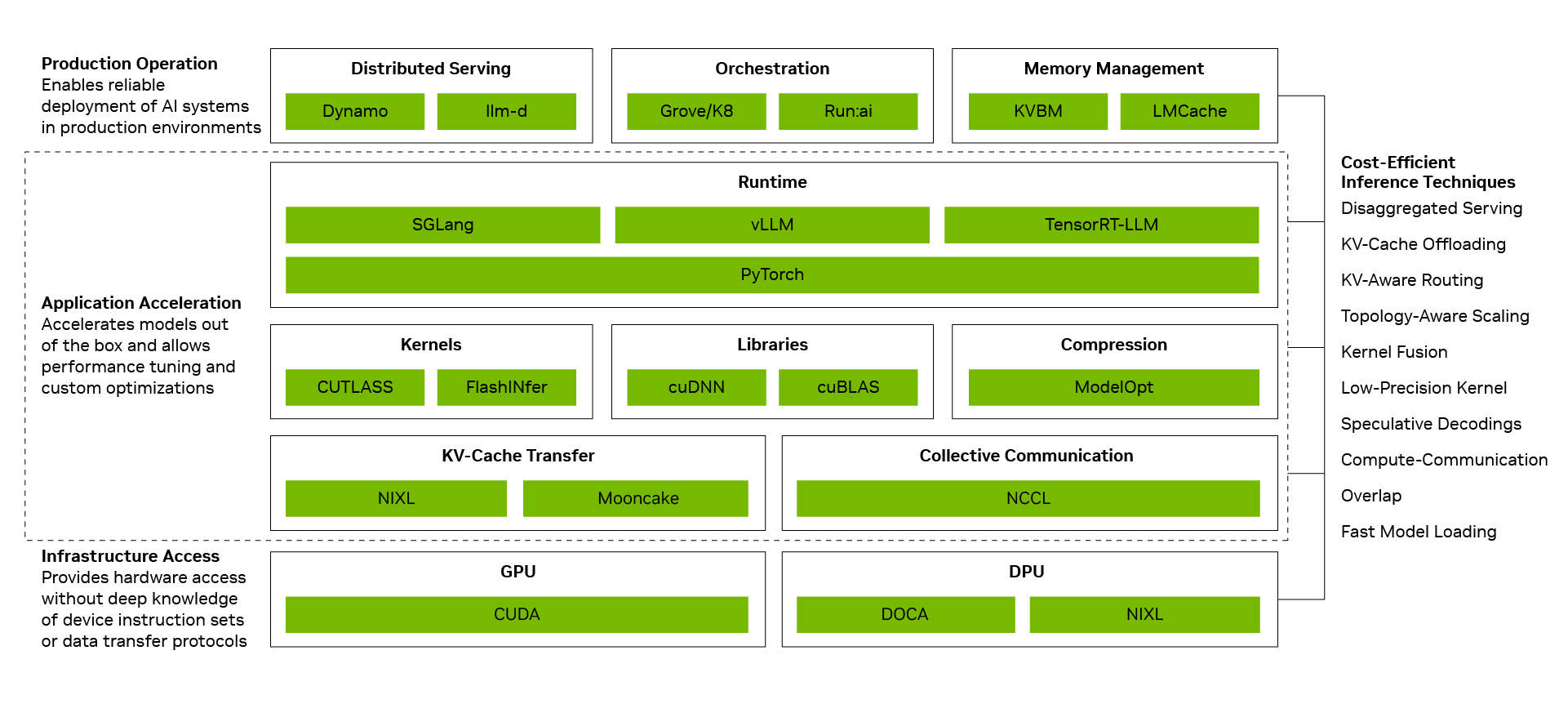
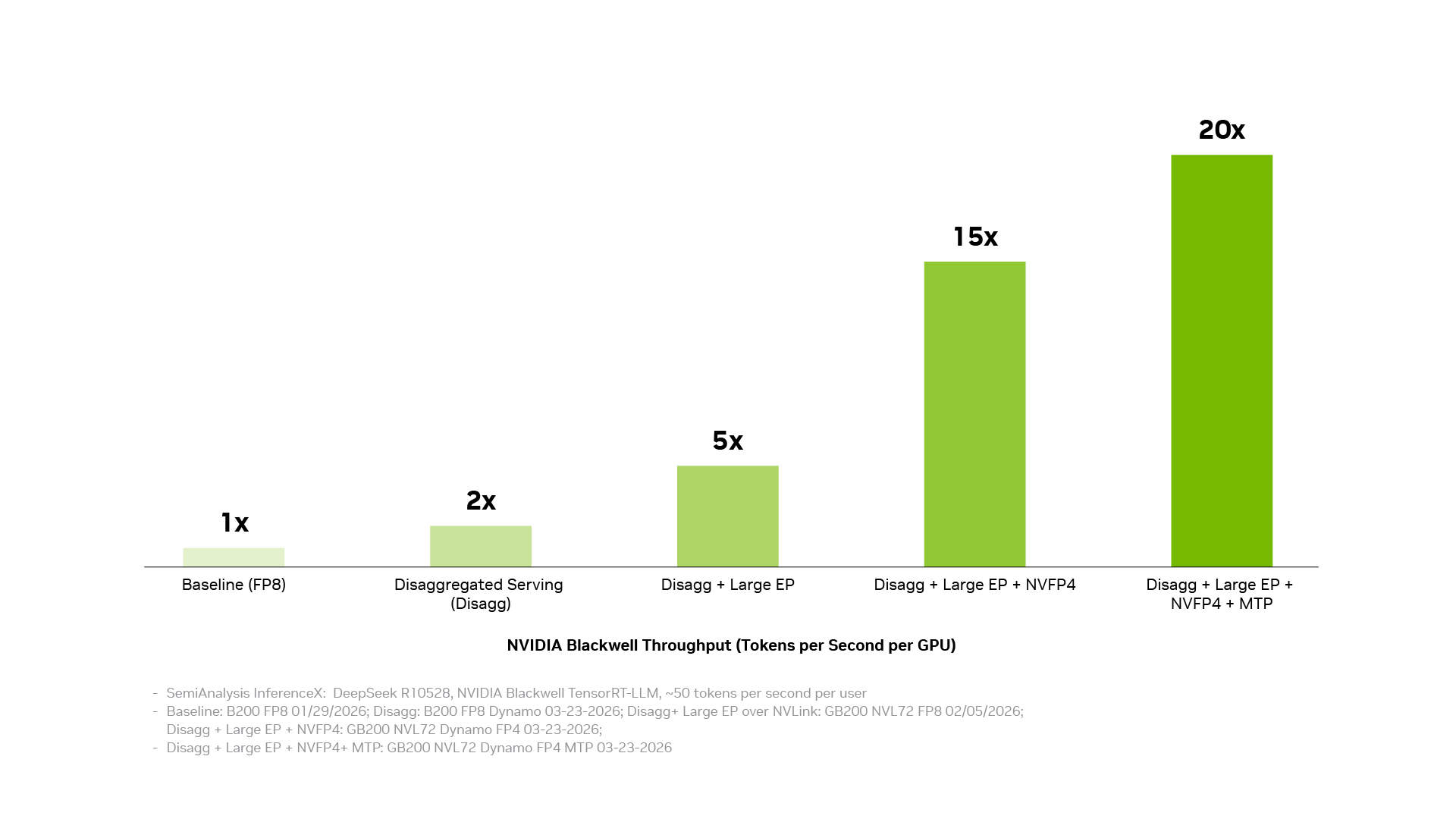
Та же самая основа полного стека также усиливается за счет экосистемы с открытым исходным кодом. Многие широко используемые сегодня фреймворки ИИ с открытым исходным кодом и проекты вывода изначально построены на базе NVIDIA CUDA. PyTorch — яркий пример: запущенный в 2016 году, он изначально поддерживает CUDA и развивается совместно с архитектурой NVIDIA. Когда такие прорывные технологии, как спекулятивное декодирование DFlash или FastVideo, реализуются в PyTorch, они могут немедленно работать на NVIDIA. Когда выходят передовые открытые модели, такие как DeepSeek V4, ведущие фреймворки вывода, такие как vLLM и SGLang, могут предоставить решения для развертывания на архитектуре NVIDIA Blackwell уже в первый день. Именно поэтому производительность DeepSeek V4 на Blackwell за один месяц увеличилась до 5 раз через фреймворки vLLM и SGLang, а стоимость одного токена снизилась примерно до одной пятой.
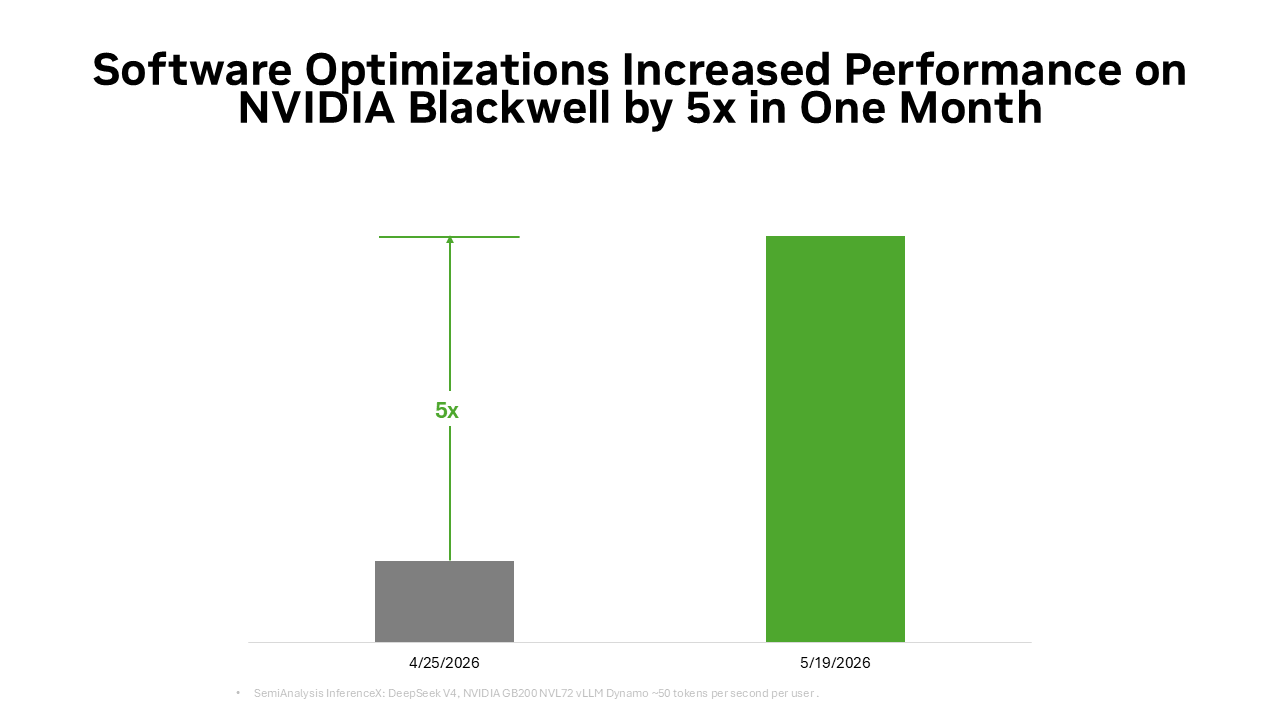
Вот как работает маховик открытого исходного кода: все больше разработчиков оптимизируют пути вывода на основе CUDA, все больше производственных развертываний возвращаются в экосистему, и каждое улучшение программного обеспечения увеличивает количество выводимых токенов, одновременно снижая стоимость одного токена.