
Репортаж от Wedoany,Китайская AI-компания DeepSeek совместно с Пекинским университетом 27 июня представила фреймворк ускорения логического вывода DSpark, предложив новый метод решения проблемы узких мест эффективности при высоконагруженном обслуживании больших языковых моделей. Фреймворк основан на направлении спекулятивного декодирования и использует полуавторегрессионную структуру генерации и механизм динамической верификации на основе уверенности для повышения качества черновых токенов и сокращения неэффективных вычислительных затрат на верификацию. В онлайн-системе DeepSeek-V4 DSpark повысил скорость логического вывода на 60–85% по сравнению с базовой моделью и снизил потери пропускной способности в сценариях с высокой степенью параллелизма.
Спекулятивное декодирование — одно из ключевых направлений ускорения логического вывода больших моделей. При генерации текста большие модели обычно предсказывают токены последовательно: следующий токен может быть вычислен только после генерации предыдущего. Такой авторегрессионный подход обеспечивает связность контекста, но затрудняет полное распараллеливание процесса вывода. Идея спекулятивного декодирования заключается в том, чтобы сначала с помощью более легковесной черновой модели заранее сгенерировать несколько кандидатных токенов, а затем целевая большая модель их верифицирует. Если кандидатные токены принимаются, можно продвинуться сразу на несколько шагов генерации, тем самым увеличив общую скорость вывода.
Проблема в том, что существующие методы параллельной генерации черновиков, хотя и позволяют создавать более длинные блоки токенов за один раз, страдают от недостаточной взаимосвязи между токенами. Последующие токены с большей вероятностью отклоняются от распределения целевой модели, что приводит к росту доли отказов. Отклоненные черновые токены не только не ускоряют процесс, но и потребляют вычислительные ресурсы на верификацию, особенно в условиях высоконагруженного онлайн-обслуживания, создавая дополнительные вычислительные потери. DSpark решает эту проблему, добавляя в параллельную генерирующую основу легковесный последовательный модуль, который усиливает зависимость между черновыми токенами и увеличивает приемлемую длину кандидатной последовательности.
Полуавторегрессионная структура является ключевой разработкой DSpark. Она не возвращается полностью к последовательной авторегрессии токен за токеном и не ограничивается простой однократной параллельной генерацией всего чернового блока, а представляет собой компромисс между эффективностью параллелизма и зависимостью последовательностей. Параллельная основа отвечает за быструю генерацию кандидатных блоков, а легковесный последовательный модуль дополняет контекстные связи между соседними токенами, приближая траекторию генерации черновой модели к целевой. Благодаря этому целевая модель с большей вероятностью принимает последовательные токены на этапе верификации, и одна верификация позволяет продвинуться на большее расстояние генерации.
Еще одним ключевым механизмом DSpark является динамическая верификация на основе уверенности. Вероятность успеха черновика варьируется в зависимости от запроса, контекста и позиции генерации. Если система использует фиксированную длину верификации, это приводит к нерациональным вычислительным затратам на запросы с низкой вероятностью успеха и не позволяет полностью использовать приемлемые черновики на запросах с высокой вероятностью успеха. DSpark адаптивно регулирует длину верификации в зависимости от вероятности успеха запроса и загрузки системы, избегая ситуаций, когда «заведомо низкая приемлемость все равно приводит к верификации слишком длинного черновика», и позволяя более разумно распределять вычислительные ресурсы при высокой нагрузке.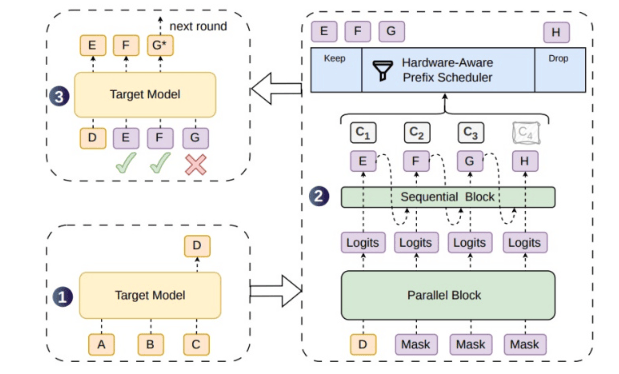
Этот механизм особенно важен для производственных онлайн-сред. В офлайн-тестовых средах запросы обычно более контролируемы, а нагрузка на параллелизм ниже. Однако в реальных сервисах больших моделей одновременно обрабатывается множество пользовательских запросов, различающихся по длине ввода, типу задачи, стилю вывода и сложности генерации. Фреймворк ускорения вывода, эффективный лишь в мелкосерийных экспериментах, вряд ли сможет поддерживать коммерческое развертывание. DSpark, продемонстрировав повышение скорости вывода на 60–85% в онлайн-системе DeepSeek-V4, подтверждает, что его разработка ориентирована на верификацию в условиях реальной сервисной нагрузки, а не просто на оптимизацию лабораторных показателей.
DSpark также улучшает пропускную способность при высокой степени параллелизма за счет увеличения приемлемой длины генерации. Стоимость обслуживания больших моделей складывается не только из задержки одного запроса, но и из общей пропускной способности кластера GPU под высокой нагрузкой. Чем выше качество черновика, тем больше токенов проходит верификацию за один раз целевой моделью и тем выше эффективный выход на единицу вычислительных ресурсов. Для API-сервисов, агентных систем, генерации кода, поисково-ответных систем и корпоративных AI-приложений снижение затрат на логический вывод означает, что те же вычислительные мощности могут обслуживать больше запросов или обеспечивать более быстрое время отклика при тех же затратах.
DeepSeek также открывает исходный код контрольных точек модели и фреймворка обучения DeepSpec, предоставляя сообществу полный инструментарий для дальнейших исследований алгоритмов спекулятивного декодирования. DeepSpec включает обучение черновых моделей, подготовку данных, скрипты оценки и реализацию различных алгоритмов, поддерживая обучение и сравнение черновых моделей, таких как DSpark, DFlash и Eagle3. Значение открытого фреймворка заключается в том, что внешние разработчики и исследовательские институты могут воспроизводить, донастраивать и оценивать его на различных целевых моделях, наборах данных и сценариях обслуживания, способствуя переходу спекулятивного декодирования от единичных алгоритмов к инженерным инструментам.
Этот результат также отражает, что конкуренция в области больших моделей смещается от масштаба параметров модели к эффективности инженерных решений для логического вывода. Возможности модели определяют верхнюю границу сервиса, а скорость вывода и стоимость единицы ресурса — скорость коммерциализации. С переходом корпоративных приложений, агентов, помощников по программированию и мультимодальных систем в фазу активного использования пользователи требуют от моделей не только «хороших ответов», но и «быстрых ответов, низкой стоимости и стабильной работы при высокой нагрузке». DSpark решает именно фундаментальную проблему эффективности при переходе больших моделей к крупномасштабному онлайн-обслуживанию.
Дальнейшие перспективы сосредоточены на трех аспектах: во-первых, сможет ли DSpark обеспечивать стабильное ускорение на большем количестве архитектур моделей и типов задач; во-вторых, сможет ли механизм динамической верификации продолжать снижать неэффективные вычисления в условиях сверхвысокой степени параллелизма; в-третьих, после открытия исходного кода DeepSpec, сформирует ли сообщество на основе DSpark больше специализированных черновых моделей для задач, связанных с кодом, математикой, длинными текстами и агентными задачами. Поскольку затраты на логический вывод становятся ключевой переменной коммерциализации больших моделей, фреймворки ускорения вывода, подобные DSpark, станут важной частью конкуренции в области AI-инфраструктуры.
Данный материал скомпилирован платформой Wedoany. При цитировании материалов, созданных с помощью искусственного интеллекта (ИИ), необходимо обязательно указывать источник — «Wedoany». В случае выявления нарушения прав или иных проблем просим своевременно информировать нас. Сайт оперативно внесёт изменения или удалит материал.Электронная почта: news@wedoany.com










