

6 июня компания Tencent Hunyuan объявила о разработке алгоритма разреженного внимания Stem, результаты которого были приняты на ведущую конференцию по машинному обучению ICML-26. Этот алгоритм направлен на устранение узкого места предварительного заполнения при обработке длинных контекстов большими языковыми моделями. Благодаря двум механизмам — затуханию позиции токена и метрике, учитывающей выходной сигнал, — алгоритм достигает точности, близкой к плотному вниманию, используя лишь 25% вычислительного бюджета, и снижает задержку первого токена в 3,6 раза в сценариях с контекстом длиной 128K.
Научная ценность Stem заключается в решении давней проблемы развертывания больших языковых моделей: чем длиннее входные данные, тем выше вычислительные затраты на самовнимание и тем дольше время ожидания перед генерацией первого токена. Длинные диалоги на основе документов, анализ кодовых баз, проверка контрактов, поиск в базах знаний, запоминание многоходовых диалогов и оркестровка корпоративных агентов — все это требует контекста длиной в десятки тысяч и даже сотни тысяч токенов. В таких сценариях скорость генерации последующих токенов, безусловно, важна, но пользователь в первую очередь ощущает «задержку первого токена» — время, необходимое системе для чтения всего длинного входа, завершения предварительного заполнения и начала вывода первого токена. Традиционное самовнимание Transformer требует масштабного взаимодействия между токенами, и с ростом длины последовательности вычислительная нагрузка быстро возрастает, поэтому разреженное внимание становится важным направлением для снижения затрат на обработку длинных контекстов. Ключевой вклад Stem заключается в том, что он не просто равномерно сокращает вычисления внимания, а переосмысливает роль токенов внутри модели с точки зрения причинно-следственного информационного потока. В структуре причинного внимания токены, расположенные в начале последовательности, постоянно участвуют в агрегации информации последующих токенов, действуя как «ствол дерева», поддерживающий передачу информации. Если разреженный алгоритм использует одинаковый бюджет для всех позиций, он легко упускает из виду рекурсивную зависимость ранних токенов в длинных последовательностях. Предложенная Stem стратегия затухания позиции токена перераспределяет вычислительные ресурсы между различными позициями без увеличения общего бюджета, выделяя больше бюджета внимания на более критические позиции в информационном потоке, тем самым уменьшая потерю точности из-за чрезмерного разрежения. Другая метрика, учитывающая выходной сигнал, решает проблему «какие токены более ценны». Предыдущие методы в основном полагались на оценки внимания для определения важности, но высокая оценка внимания не обязательно означает большой вклад в конечный вывод; амплитуда информации, переносимая вектором Value, также влияет на результат. Stem объединяет вероятность маршрутизации и вклад выходного сигнала для оценки ценности токена, делая разреженный выбор более соответствующим фактическому процессу вывода модели. Такая конструкция превращает разреженное внимание из простого сокращения вычислений в выбор, основанный на информационном потоке и вкладе в вывод, предлагая более детальный алгоритмический путь для вывода с длинным контекстом.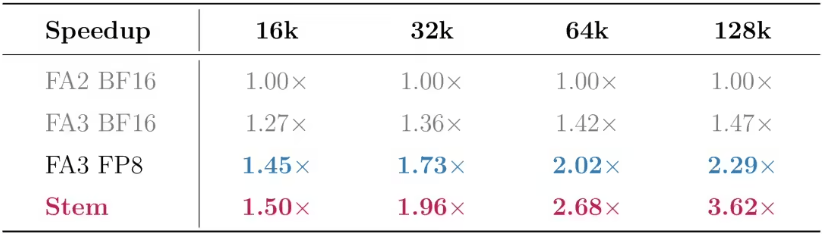
Что действительно влияет на внедрение в промышленности, так это возможность преобразовать алгоритмические выгоды в измеримое ускорение на аппаратном уровне.
На этот раз Tencent Hunyuan одновременно представила полностековое решение, объединяющее алгоритм Stem с библиотекой HPC-операторов, что устраняет ключевой разрыв между теорией разреженного внимания и его развертыванием. Многие разреженные алгоритмы могут сокращать объем вычислений в экспериментальных статьях, но при внедрении в систему вывода на GPU могут возникать дополнительные накладные расходы из-за выбора блоков, индексации, пропуска блоков, перемещения данных и доступа к кэшу, в результате чего сквозное ускорение оказывается ниже теоретических ожиданий. Сопровождающие Stem операторы HPC-Stem и HPC-BSA решают эту проблему с помощью инженерной оптимизации: первый ускоряет процесс оценки и выбора блоков, второй оптимизирует процесс блочного разреженного внимания, позволяя пропущенным вычислительным блокам действительно сокращать нагрузку на GPU. Особенно в производственных условиях, таких как архитектура Hopper, FP8-квантование, Paged KV Cache и фреймворк вывода vLLM, стабильность выгод от разрежения напрямую определяет практическую ценность алгоритма. Tencent Hunyuan интегрировала Stem в сценарий вывода с W8A8-FP8-квантованием в предварительной версии Hy3 и достигла снижения задержки первого токена в 3,6 раза в контексте длиной 128K, что свидетельствует о том, что решение вышло за рамки чисто академической проверки и начало оптимизироваться для промышленных конвейеров вывода. Для корпоративных приложений больших языковых моделей значение таких улучшений очевидно: при одинаково длинном входе система быстрее завершает предварительное заполнение, что значительно улучшает пользовательский опыт ожидания; при том же наборе GPU повышение эффективности обработки запросов с длинным контекстом снижает стоимость обслуживания и увеличивает способность платформы обрабатывать более сложные задачи. По мере дальнейшего расширения контекстного окна моделей предприятия будут стремиться не только к тому, «насколько длинный текст может прочитать модель», но и к тому, «чтобы она читала быстро, с низкими затратами и стабильной точностью». Stem объединяет информационный отбор на алгоритмическом уровне с аппаратным выполнением на уровне операторов, расширяя оптимизацию вывода длинных текстов от исследований структуры модели до协同 работы вычислительных систем, что и делает его важным научно-техническим достижением.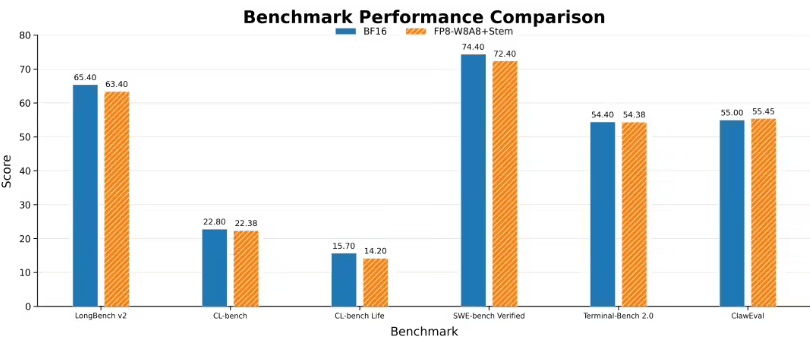
Это достижение также указывает на то, что конкуренция в области больших языковых моделей переходит на более глубокий инфраструктурный уровень. Раньше улучшение возможностей моделей в основном проявлялось в масштабе параметров, обучающих данных, точной настройке инструкций и экосистеме приложений; теперь, когда длинный контекст стал основной возможностью, предварительное заполнение, KV-кэш, разреженное внимание, квантованный вывод, оптимизация операторов и системы планирования начинают определять, может ли модель работать с низкими затратами. Появление Stem показывает, что китайские команды разработчиков больших языковых моделей переносят акцент своих исследований на协同 оптимизацию алгоритмов, операторов и фреймворков вывода, а не конкурируют только в параметрах моделей и рейтинговых баллах. Для отраслевых приложений в финансах, государственном управлении, промышленности, медицине, юриспруденции и научных исследованиях, где требуется обработка длинных документов, снижение задержки первого токена напрямую повлияет на удобство использования системы: проверка контрактов не будет требовать длительного ожидания, ответы на вопросы по базам знаний смогут обрабатывать более длинные контексты, агенты смогут сохранять больше исторической информации в более длинных цепочках задач, а ассистенты разработчиков смогут считывать больше кода и документации за один раз. Если в будущем алгоритм Stem и открытые операторы будут расширены на большее количество моделей, аппаратных архитектур и более длинные контекстные окна, его ценность не ограничится экосистемой Tencent Hunyuan, но может стать универсальным методологическим ориентиром в области эффективного вывода длинных текстов.
С технической точки зрения, прорыв Stem заключается не в простом стремлении «меньше вычислять», а в сжатии наиболее дорогостоящих вычислений внимания при выводе длинных контекстов больших языковых моделей до более развертываемого диапазона с минимальной потерей точности. По мере развития контекстов с миллионами токенов, корпоративных агентов и сложных мультимодальных задач задержка первого токена станет важным показателем инженерного мастерства больших языковых моделей. Это достижение Tencent Hunyuan предлагает новый путь оптимизации для вывода с длинным контекстом и продвигает разреженное внимание от алгоритмических статей к реальному аппаратному ускорению и проверке в производственной среде.